直播弹幕数据如何爬取?
现在随着直播越来越风靡,越来越多人沉迷其中,直播中的弹幕也是人们喜欢看直播的一个原因,现在我们就针对直播中的弹幕进行爬取,由于我们只想跑一次程序,所以我下面就针对录播的弹幕进行爬取。
我们选取了我比较喜欢的英雄联盟主播东北大鹌鹑 作为我们弹幕的爬取对象,看看我们的嘟嘟怪的弹幕是不是这么好玩。
一.导入爬虫所需的python库

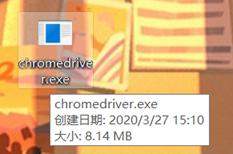
由于斗鱼直播网页是动态网页,所以我们采用了selenium这个自动化测试工具进行爬取,在使用这个模块之前,需要先安装chromedriver,而且chromedriver的版本需要和你的chrome浏览器版本对应。
二.分析网页
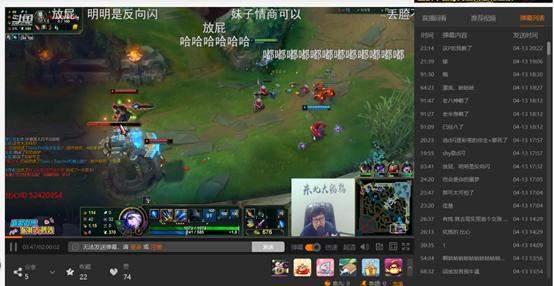
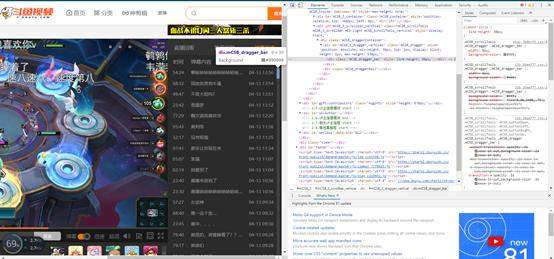
我们使用谷歌浏览器的开发者工具F12看一下我们的目标,首先进入到这个录播的页面,然后有一个弹幕列表的这个按键,我们需要点到这个按键:
点击之后,弹幕就在右边排列出来,这就是我们想要的结果,我们下一步的目标就是,希望点击拖动条,然后把弹幕的内容和弹幕的发送时间全都保存下来:
三.开始敲代码
先初始化这个类,设置一下参数,代码如下:

我们在分析的网页的时候已经提到过,需要先点击弹幕列表,这样网页才能更新出弹幕的内容,代码如下:

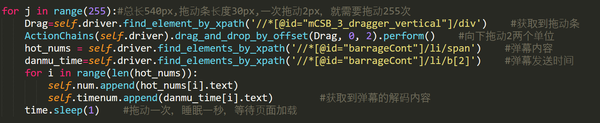
经过上一步之后,网页内容已经更新,我们下面要获取到弹幕的内容以及弹幕的发送时间,还是通过xpath,通过selenium得到的是一个数据,可以把当前页所有弹幕内容和弹幕发送时间获取到 ,还有一点就是,点击之后,不能立马就获取,需要等待页面加载完成,不然获取不到东西 代码如下:
我们现在已经获取到当前页的所有弹幕和所有弹幕的发送时间,我们要进行下一步,就是滑动拖动条,继续更新我们的弹幕列表,通过chrome的开发者工具,获取到拖动条长度为30px,总长是540px,通过调试可知,拖动条一次拖动2px,可以刚好更新整个弹幕内容:
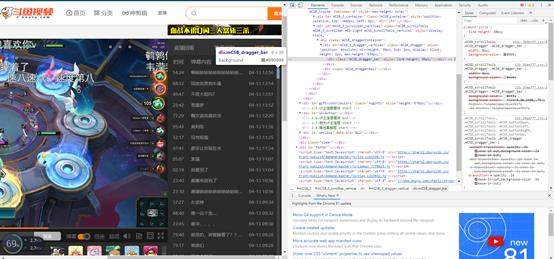
所以我们直接上代码:
四.将爬取的结果保存到文件
目前将爬取到的结果保存下来的方式有两种,一种是保存到本地文件(txt,csv,….),还有一种保存到数据库
1.保存到本地文件,直接上代码:

2.保存到数据库

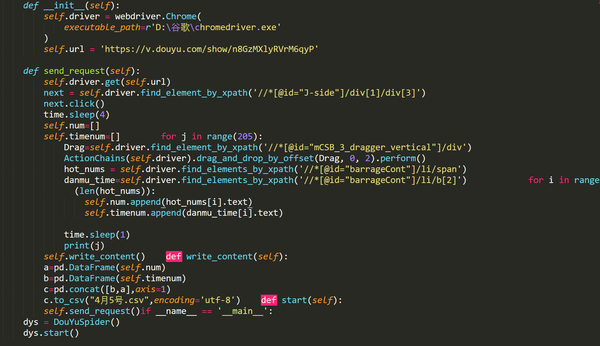
五.爬虫的完整代码:
六.对爬下来的弹幕做词云分析
现在我们已经已经把斗鱼的弹幕爬取了下来,我们就需要对爬取的内容进行一下简单的分析,这次我选择做一个词云,看看主播弹幕主要的关键词都是些什么,咱们说干就干:
首先我们要用到wordcloud这个词云模块,需要自己先行安装,还需要安装一个字体包,连接如下:
s3-us-west-2.amazonaws.com/notion-static/b869cb0c7f4e4c909a069eaebbd2b7ad/simsun.ttf
接着下载simsun.ttf。
由于中文文化博大精深,我们需要先对中文的句子进行分词,中文分词的工具有很多种。有的免费,有的收费。
今天给大家介绍的,是如何利用Python,在你的笔记本电脑上,免费做中文分词。
我们采用的工具,名称很有特点,叫做“ 结巴分词 ”,大家可以通过pip install jieba来安装这个工具。
七.结果展示

怎么样,是不是很符合东北大鹌鹑的主播形象呢?国服第一艾希的嘟嘟嘟,日常带比心小姐姐套路怪,日常直播到屁股疼不得不停播的鹌鹑哥。
相关推荐
-

B站直播弹幕怎么举报(b站直播怎么举报弹幕啊)
2016年,网络直播空前火爆.然而其疯狂扩张.野蛮生长的同时也滋生了很多问题.除了主播层面,弹幕作为直播平台拉动主播与观众最主要的互动方式,问题也非常突出.但面对那么多"辣眼睛"的 ...
-
python网易云音乐爬虫原理(python爬取付费音乐)
在开始之前,做一点小小的说明哈:我只是一个python爬虫爱好者,如果本文有侵权,请联系我删除!本文需要有简单的python爬虫基础,主要用到两个爬虫模块(都是常规的)requests模块seleni ...
-
虎牙直播弹幕颜色怎么换?
虎牙直播弹幕颜色变化教程 赠送10个荧光棒,弹幕的颜色就会变了! 成为主播的粉丝,就会根据主播的身价,弹幕也会随之改变.
-
手机天猫app怎发送直播弹幕?
手机天猫app怎发送直播弹幕?观看天猫直播的时候,总是看到很多弹幕,自己也想发,该怎么发呢?下面我们就来看看天猫app观看直播并发弹幕的教程,需要的朋友可以参考下. 1.首先下载天猫app,打开进入天 ...
-
小米直播app怎么关闭直播弹幕?
小米直播app怎么关闭直播弹幕?使用小米直播app看直播的时候,总是被弹幕刷屏,啥也看不到,想关闭直播弹幕,该怎么关闭呢?下面我们就来看看详细的教程,,要的朋友可以参考下 1.下载小米直播app,点击 ...
-
手机钉钉中直播的数据信息在哪查看
有的朋友经常需要使用钉钉来直播,今天小编就告诉大家手机钉钉中直播的数据信息在哪查看.具体如下:1.首先我们打开手机中的钉钉APP,在界面中点击直播的群.2.然后在窗口中点击右上方的"-&qu ...
-
手机版钉钉如何查看群直播的数据信息
手机版钉钉软件被很多人使用,用来工作或者学习等,那么如果在群直播后,想要知道直播时的数据,但是却不知道如何查看数据信息,那么小编就来为大家介绍一下吧.具体如下:1. 第一步,点击并打开钉钉软件,接着点 ...
-
如何在电脑版钉钉查看直播回放数据
现在很多学校在使用钉钉上网课,为了避免学生错过课程通常会录制直播,有些用户想知道如何在电脑版钉钉查看直播回放数据,接下来小编就给大家介绍一下具体的操作步骤.具体如下:1. 首先第一步打开电脑中的[钉钉 ...
-
如何设置斗鱼直播弹幕
现在很多年轻人喜欢使用斗鱼直播,有些用户在看直播时想知道如何设置弹幕,接下来小编就给大家介绍一下具体的操作步骤.具体如下:1. 首先第一步打开手机中的[斗鱼直播]App.2. 第二步进入软件后,打开需 ...
-
如何关闭抖音直播弹幕
抖音是现在非常热门的一款短视频软件,最近推出了直播功能,有些用户想知道如何关闭抖音直播弹幕,接下来小编就给大家介绍一下具体的操作步骤.具体如下:1. 首先第一步打开手机中的[抖音]App,进入软件后根 ...
