python 大量乱序文件如何合并成有序的
本文以爬取一部小说为例,因使用的是多线程爬取,所以每个小说章节都是一个txt文件,而这些文件都是乱序的,要阅读的话我们也不可能每阅读一章小说就去翻另一个txt文件,这时就需要合并了.
----------------------------------------
爬取时间2022/8/16
代码如下:
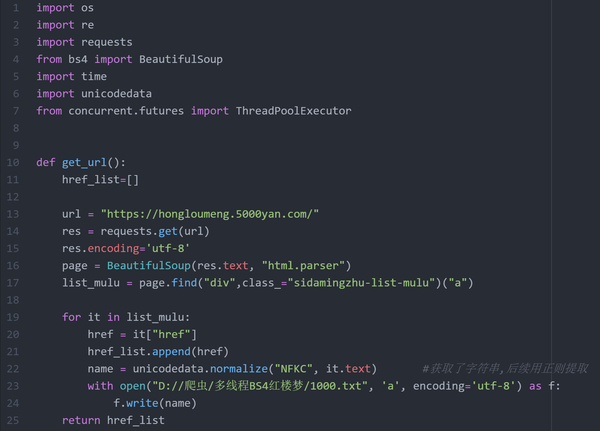
代码1-25行
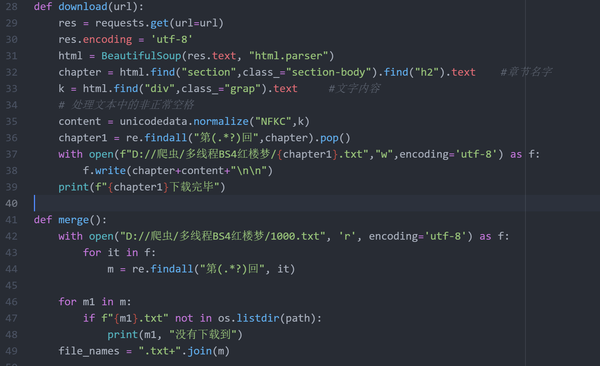
代码28-49行

代码50-75行
运行结果:

pycharm中的结果
文件管理器中的结果
从结果中可以看到,程序从运行到结束,一共花了3秒钟,
三秒内做完了从网站获取url链接,再通过120个url下载了120个txt文件,合并成一个大的txt文件后,再删除之前的120个小txt文件.
----------------------------------------------
代码10-25行>>>
从主页面发起请求,结合bs4和正则获取了小说每个章节的url链接和名字,并将顺序正常的名字写入叫1000.txt的文件. 第22行用unicodedatach处理了文本中的非正常空格(类似 )
代码第28-39行>>>
以每个章节的url为函数参数,获取了小说内容,并写入txt文件,
用章节名 (例如: 第四十九回 琉璃世界白雪红梅 脂粉香娃割腥啖) 作为xxt文件的名字. 因为原本的章节名含有空格以及非正常空格,不利于后续排序处理,就采用正则提取了 "第"和"回"中间的文字作为txt文件名.
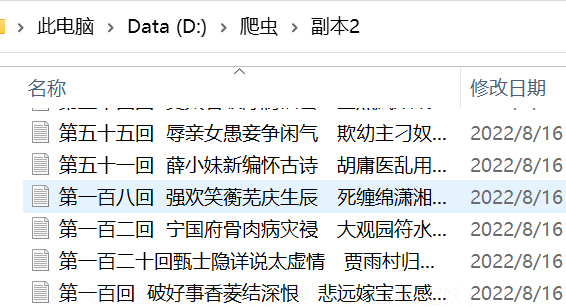
不用正则处理xtxt文件名就是这个样子
代码第69-71行>>>
创建了线程池下载txt文件
代码第41-55行>>>
打开名为1000.txt文件,提取里面的正常顺序的章节名,以此作为已下载的120个txt文件的合并顺序.
代码第57-61行>>>
将之前下载的120个小txt文件删除,保留合并后的大的txt文件,接下来就可以愉快地阅读小说了
手机中显示的效果
注: 将ts文件合并成MP4文件也是通用的,但需要注意的是使用os模块单次合并ts文件数量在650个左右,不到700个.
至于用os模块单次合并txt文件的数量限制是多少,暂时未测试.
----------------------------------------------
最后:源码以及小说txt文件,封面原图链接阿里云盘分享