百度智能匹配和短语匹配哪个好
导读:我们在实现检测一个字符串是否包含另一个字符串时,简单的用一个字符串匹配算法就可以实现,如果要实现检测一个字符串是否包含 N 个字符串时,这个 N 有可能上千万,再利用简单的字符串匹配算法就没法满足我们的需求了,上千万的词需要可以灵活的维护,业务方匹配时能够拿到自己的词进行匹配,千万词的匹配需要保证匹配速度,要在秒级之内出结果。所以,我们需要一套解决此类问题的方案——词表服务 。
全文5370字,预计阅读时间 12分钟。
一、背景
内容审核平台需要检测作者发的文章中是否含有特殊的敏感词。对于不同的业务线对这些词的要求也不同,有的严格有的宽松;有的需要单词,有的需要多词;有的需要检测出隐含词、变体词;有的在标题生效,有的在正文生效;有的检测出送人审,有的检测出直接拒绝;有的需要几千词,有的需要上万、百万、甚至千万词。对于这些词各业务线可以自己维护,方便增加、删除、修改,各业务可以根据自己的需求配置词的生效规则;在检测的时候业务方可以拿到自己维护的词对文章进行检测,而且需要保证检测的时效,能够实时拿到检测结果。
二、架构
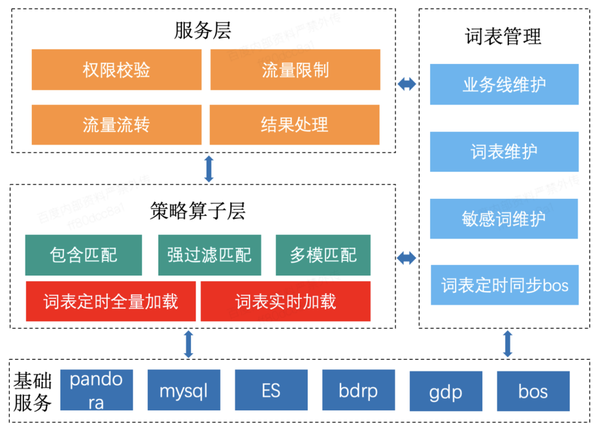
上图是词表服务的整体架构:
(1)词表管理:各业务线在词表管理平台维护自己的词表,每个业务线可以添加多个词表组,每个词表组中可以维护敏感词以及可以动态添加敏感词的属性;词表管理平台用ES实现了对词表及上千万词高效的分词检索能力;词表管理会定时生成各业务线的词表BOS文件,上传到BOS服务。
(2)服务层:业务方调用词表服务统一对外的匹配接口,服务层将匹配任务送到策略算子层,完成词表的匹配功能。词表对外的统一服务相当于一个简单的网关,提供了鉴权功能,验证请求是否合法;提供了流量限制的功能,可以为每个请求方设置流量限制值;提供了结果处理的功能,策略算子返回的敏感词属性只是一部分,根据业务方的需求,可以完善策略算子返回的敏感词属性;提供了流量转发的功能,可以根据配置将各业务线的请求打到不同的集群,实现各业务策略算子分集群部署。
(3)策略算子层:策略算子实现对文本中敏感词的匹配,匹配的模式有包含匹配、强过滤匹配、多模匹配,命中的敏感词会返回给词表服务层。各业务线的词表会被策略的每个算子用全量刷新的方式或者实时同步增量数据的方式加载到内存,支持算子的匹配功能。全量刷新的方式:词表管理平台会定时将词表分业务线生成BOS文件,上传到 BOS 服务,策略算子定时从BOS文件中同步敏感词到内存;实时同步的方式:策略算子会实时扫描刺词表数据库,将增量的词表加载到内存。
(4)基础服务:GDP框架实现了词表服务开发,Pandora平台实现了词表服务的部署,mysql 实现了词表数据的存储,ES实现了词表的分词检索,bdrp实现了限流及缓存功能,BOS服务实现了词表文件的的传输。
三、词表管理平台
词表管理平台,实现了各业务线维护自己的词表,每个业务线下可以创建多个词表组,方便业务方分类管理自己的敏感词,每个词表组的含义由业务方赋予,具体体现在当命中的敏感词属于这个词表组的时候,业务方是否根据词表组做不同的处置;每个词表组下可以维护敏感词,敏感词的属性由业务方自己选择,例如,审核类型这个属性,业务方可以根据命中具体某个敏感词后要送审,就选择送审词这个属性值,如果要拒绝就选择拒绝词这个属性值。
3.1词表管理
各业务线可以添加、修改的词表,可以对词表进行检索。
(1)新增词表,选择属于的业务线,添加名字和备注,可以一次将词表创建到多个业务线下,如果其他业务线有词表可以复用,也可直接将其他业务线的词表拷贝到自己新建的词表下,方便快捷,方便管理人员对词表的管理。如图1:

(1)修改词表,可以修改词表的名字、备注,可以将词表重新指定业务线,如果其他业务线有词表可以复用,也可直接将其他业务线的词表拷贝到自己的词表下,方便快捷,方便管理人员对词表的管理。如图2:

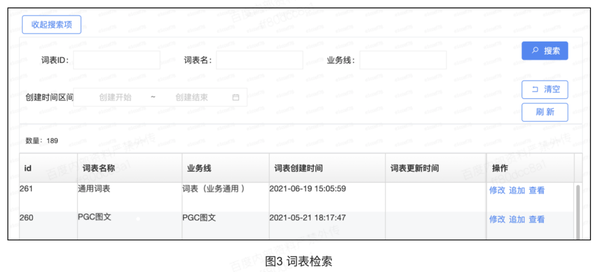
(2)词表检索,支持通过词表ID、词表名称、业务线以及创建的时间检索词表;词表名称的检索,利用了 ES 的特性可以实现对词表名称进行分词检索;在检索到的列表中,可以看到词表的id、词表名称、业务线、词表的创建时间、更新时间、每个词表下的词条数量、词表备注、词表的生效状态操作人等词表属性;可以在列表中状态中点击,将词表改成生效或失效状态;在操作栏可以点击修改,修改词表,点击追加给词表添加词,点击查看查看词表的详情信息。如图3:
3.2敏感词维护
在词表中可以高效快捷的维护敏感词。重要的敏感词的属性包含:
(1) 词条类型:标识敏感词是送审词还是过滤词;
(2) 敏感类型:标识词条的敏感分类;
(3) 匹配模式:包含匹配-检测本文中是否包含敏感词,强过滤匹配-检测文本中汉字、字母、数字、特殊字符相互组合后是否包含敏感词,多模匹配-检测文本中是否命中2个或3个词,且多个词间距在有效范围内。
(4) 生效位置:敏感词在文章中的生效位置,如,标题、正文、图片中给的文字等。
(5) 豁免词:包含匹配中敏感词的属性,如果敏感词是A,豁免词是B,文本中有AB词,则敏感词A不会命中。
(6) 延展策略:多模位置置换-如果有多模词AB,文本中有词BA,则可以命中AB敏感词;字母大小写转换-忽略大小写,如果敏感词是cd,文本中有cD、Cd、CD词,则都可命中cd词。
(7) 失效时间:提供了长期有效和具体失效时间两种选择。
敏感词维护提供了单条添加、批量添加、单条修改、批量修改、词表检索、词条检索等功能:
(1)单条追加,追加的词表名称已经确定,业务方可以根据自己的业务选择词的属性,追加中的操作,如果词的匹配模式属性选择了包含词,可以添加这个词的豁免词。如图4:

(2)批量添加,支持同步最大一次添加3000条,可以同时添加到不同业务线的不同的词表中,方便快捷,方便了管理员对敏感词的维护工作,要添加的所有的敏感词属性必须一致才可以使用此功能,二期不支持给包含词添加豁免词属性,可以在敏感词输入框中换行输入多条。如图5:

(3)批量创建,业务方可以根据自己的业务将敏感词及属性维护到EXCEL表中,每个文件最大支持3万词,提交后,可以生成一个创建任务,后台运行,同时可以创建多个任务,执行的时候是顺序执行,如图6:

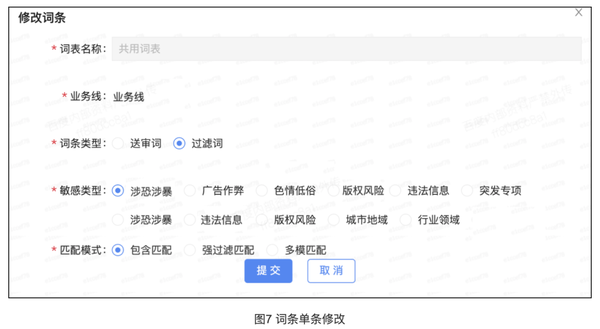
(3)单条修改,可以修改词条的任意属性,如果敏感词是同步批量添加的包含词,想要添加敏感词的豁免词可以在这里修改。如图7:
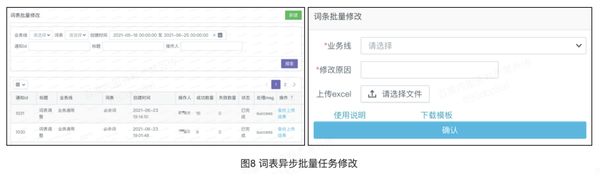
(3)批量修改,业务方可以根据自己的业务将敏感词及要修改的属性维护到EXCEL表中,每个文件最大支持3万词,提交后,可以生成一个更新任务,后台运行,同时可以创建多个更新任务,执行的时候是顺序执行。如图8::
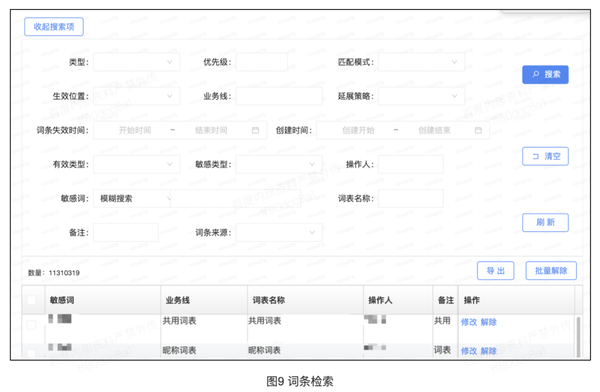
(4)敏感词检索,可以根据敏感词的审核类型、匹配模式、生效位置、敏感类型、操作人、所属业务线、所属词表、敏感词的创建时间等属性检索,敏感词的检索使用了ES分词检索的特性,可以支持分词检索,也可以实现精确检索;检索的列表中展示了敏感词的名称、所属业务线、所属词表、操作人、操作时间、备注等字段,可以查看总体数量,可以导出,批量解除,操作栏中,可以点击修改,进入修改页面,可以点击解除,解除此条敏感词。如图9:
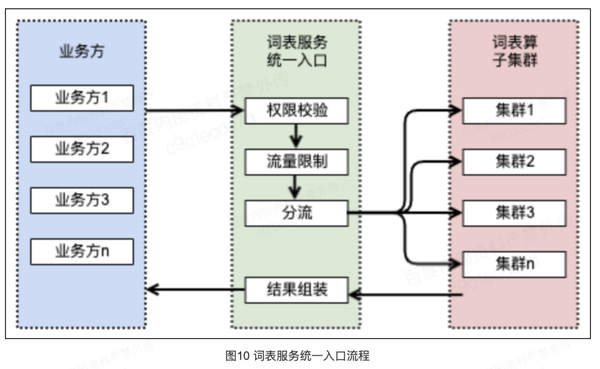
四、词表服务统一入口
词表服务统一入口,提供了标准的 API 接口,业务方调用词表服务统一对外的匹配接口,服务层将匹配任务送到策略算子层,完成词表的匹配功能。词表对外的统一服务相当于一个简单的网关,提供了鉴权功能,验证请求是否合法;提供了流量限制的功能,可以为每个请求方设置流量限制值;提供了结果处理的功能,策略算子返回的敏感词属性只是一部分,根据业务方的需求,可以完善策略算子返回的敏感词属性;提供了流量转发的功能,可以根据配置将各业务线的请求打到不同的集群,实现各业务策略算子分集群部署。具体的流程,如图10。
五、策略加载词表
策略加载词表经过多方案的迭代,方案最终逐渐成熟稳定。
第一版词表在策略的生效方案:词表管理平台将所有的业务线的词表生成一个词表文件,上传到BOS,词表策略30min定时扫描加载一次。所有业务线集中到一个词表文件中,一次加载,导致了策略加载词表速度慢。
第二版的方案,30分钟生效时间后来不能满足业务方的需求,词表管理平台按照业务线生成多个词表文件,推送到BOS系统,词表策略定时,分业务线开启多线程加载词表,词表生效时间由 30min 减少到5分钟。
单三版方案,5min钟时间对于特殊场景还是不满足,我们增加了词表实时同步方案,由词表策略10s定时去数据库扫描增量的数据加载到内存,但是这种方案不适合上万的增量数据加载,只适合万级以内词的加载。
现在词表策略加载词表,第二版和第三版同时存在,优势互补,整个演变过程如图11:

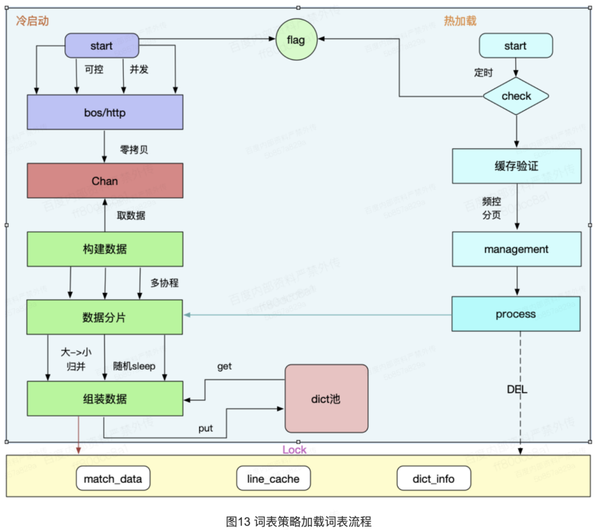
BOS文件格式,多列用制表符分割,多模词用 & 符号连接,包含词添加前缀 号识别,主要的信息有敏感词id、敏感词名称、敏感词所属词表id、多模词词间距、失效时间、审核类型、匹配类型、所属业务线、生效位置、敏感类型、延展策略、豁免词。如图12:

全量加载和增量实时同步加载流程,全量加载会在启动的时候加载一次,加载的频率半个小时以上,可以根据业务线配置;增量实时同步10s中去数据库检测一次是否有增量数据,然后分页加载到内存。如图13:
策略缓存词表到内存的加载结构,如下:
(1)业务线、生效位置,敏感词,敏感词id 字典映射。匹配到敏感词,可以根据业务线,生效位置,快速的找到敏感词的id,通过敏感词的 id 再获取敏感词的属性规则,用于计算匹配到的敏感词是否有效。如图14:

(2)敏感词id及敏感词属性规则字典映射,BOS文件每行敏感词处理存储。通过敏感词ID能够快速查到敏感词的属性规则,用于计算匹配到的敏感词是否有效。如图15:

(3)敏感词挂在到字典树(Trie树),每个业务线、生效位置生成一个字典树,字典树是词表策略的核心,上千万的敏感词匹配能在10ms以内返回配置结果。如图16:

六、词表策略匹配实现
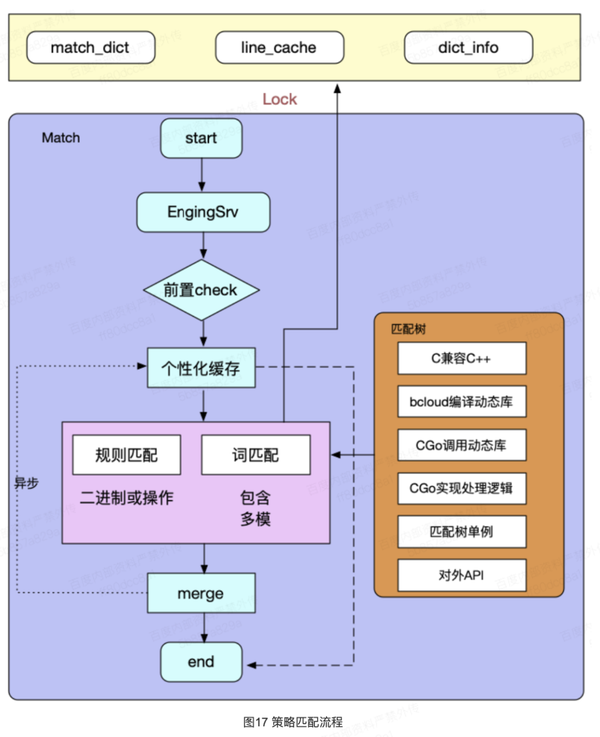
6.1词表策略匹配流程
策略配置匹配流程,如图17:
(1)输入匹配参数,request_id请求的唯一标识,用于上下游定位,req_from请求来源,用于识别请求业务方,token用于权限校验,service_line业务线标识,用于识别匹配用的词表,conent要匹配的文本,以及文本的配置,用于识别需要哪个生效位置的敏感词。如图18:

(2)将文本中的中文、字母、数字、特殊符号抽取组合生成不同组合的文字片段,用于强过滤匹配。如图19:

(3)根据业务线以及文本的位置将文本送到对应的字典树匹配出单个敏感词,信息包含敏感词、敏感词在文本中的位置、敏感词的长度,位置和长度用于多模词,词间距是否有效的计算。匹配出的结果,如图20:

(4)通过业务线,生效位置、敏感词,从 match_data(图13)缓存中获取到敏感词所属的敏感词ID,再通过敏感词ID从line_cahe缓存中获取到敏感词的属性规则;如果匹配到的敏感词是包含词或者过滤词,直接命中输出;如果是多模词,则再查找多模词中的其他词是否命中,如果命中切两个词的顺序和词间距满足多模词的属性规则,则命中输出。结果返回,如图21:

6.2大文本匹配超时解决方案
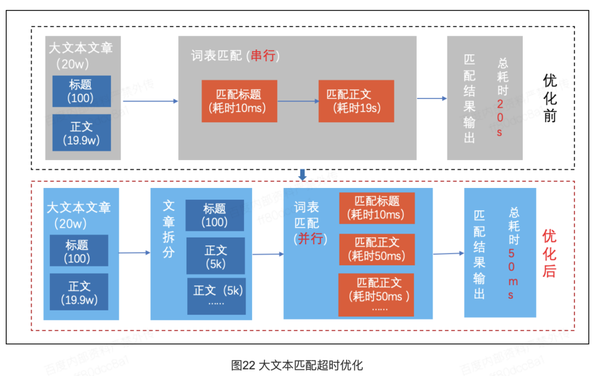
PGC图文经常有几十万字的大文本文章过词表,由于字数太多,召回的词量能达到几万,这些词在做匹配规则计算时耗时太长,导致匹配超时。
优化方案如图21:
(1)优化前,一个大文本文章,标题字数100,正文19.9w,词表匹配时先匹配标题,耗时10ms,再匹配正文,由于正文字数多,耗时19s,最终匹配的耗时两者累加达到20s。
(2)优化后,大文本文章过词表,先将字数超过5000的正文,拆成多个小于等于5000的正文,词表匹配时,多个文字片段并行匹配,最终耗时结果是多个并行计算中耗时最大的一个,我举的例子50ms。
6.3 字典树(Trie树)的实现
字典树匹配算法使用了厂内的开源C 库 dictmatch,dictmatch实现了最简单的Trie树的算法,没有进行穿线改进,因此是需要回朔的。但是其使用2个表来表示Trie树,并对其占用空间大的问题进行了很大的优化,特点是在建树的时候比较慢,但在查询的时候非常快。
字典树结构,如图23:

七、发展&思考
词表特殊字符支持:现在的词表词的存储以及字典树的匹配算法对于表情及其他特殊字符不支持,词表服务下一步的优化迭代会主要放在特殊字符的支持上,能够满足更多业务的需求。
词表分业务线部署:现在词表服务 60 的业务方,各业务线都是混部,所有业务线的词表都在实例中加载一份,耗费内存特大,而且词表服务出问题会影响所有的业务方;如果每个业务线都分集群部署,会增加维护成本,所以我们在探索一种自动分业务线部署的方式。
作者:百度Geek说
链接:
https://juejin.cn/post/6986882343998849060
来源:掘金
相关推荐
-
百度智能聊天机器人是真的吗? 超能无敌霹雳聊天宝详情
百度智能聊天机器人是真的吗?最近有很多朋友在问超能无敌霹雳聊天宝聊天机器人是不是真的,这么狂(sang)拽(xin)酷(bing)炫(kuang)的名字,到底是不是真的呢? 日前,百度新闻官微博放言, ...
-
如何申请百度智能小程序?
智能小程序是研发的产品,2018年7月4日,智能小程序正式上线.很多人都想知道,如何申请智能小程序呢?跟着这篇教程来看看吧! 操作方法 01 智能小程序开发者后台登录地址:https://smartp ...
-

百度智能小程序怎么使用
一.已有熊掌号快速注册如何快速注册百度智能小程序?简单最快的方法是:通过已经认证的熊掌号直接申请百度小程序,这样就可以不需要一步步的注册.但通过熊掌号一键创建百度小程序,还需要后台完善小程序基本相关信 ...
-
vlookup模糊匹配和精确匹配区别(vlookup函数的模糊匹配)
各位读者朋友们大家好,今天来给大家解决群里经常提问的第二个问题,如何用简称匹配全称.这个用法在Excel中我们称之为查找值的模糊匹配,我们实际工作中经常遇到,同事将某个产品或者是公司名称等用简称来代替 ...
-
百度智能认证人脸识别(百度人脸识别认证)
百度智能认证人脸识别(百度人脸识别认证)
-
百度竞价基本知识
搜索推广,是一种按效果付费的网络推广方式,是推广的一部分,如果做得好,即可用少量的投入给公司带来大量潜在患者,有效提升公司网站的流量.咨询量.预约量.公司品牌知名度. 操作方法 01 一.什么是百度竞 ...
-
QQ影音1.6版新功能 自动匹配显示歌词
同步显示歌词犹如给欣赏音乐添加了翅膀,带来更完整的视听享受。但国内主流视频播放器多数不带歌词功能,即便具备此功能也常不够完善,比较遗憾。 QQ影音近期发布的1.6版本中,新增了自动匹配显示歌词的功能, ...
-
oppor7可以与小米手环匹配吗
一.oppor7可以与小米手环匹配吗? 1.oppor7的操作系统为Color OS 2.1(基于Android OS 4.4). 2.小米手环支持安卓4.4及以上的系统. 3.所以oppor7是可以 ...
-
如何使用网易云音乐匹配本地缓存音乐文件?
方法 打开电脑中安装的网易云音乐客户端,然后点击左侧的本地音乐. 出现的本地音乐窗口中,点击蓝色的选择目录.然后添加歌曲文件. 添加缓存歌曲文件所在的文件夹,勾选文件夹,从而添加歌曲文件. 这时候网易 ...
-
excel怎么从数据源中匹配到相关值?
excel怎么从数据源中匹配到相关值? 1.我们通过函数 =vlookup(lookup_value,table_array,col_index_num,[range_lookup]) .来解决这个问 ...
