Excel怎么把有公式的数据变成数字格式(Excel文本里的数字怎么变成数值格式)
在你眼里,“10”跟“10”有什么区别吗?
答案当然是没有。但在Excel里,“10”跟“10”可能完全不是一个东西。一个非常简单明了的例子,“119”可能是火警电话,还可能就是数字119。
这就引入了我们今天要说的一个概念:文本型数据。
什么是文本型数据
在Excel里,常见的数据分为数值型、日期型、文本型、逻辑型数据等几大类,其中,比较容易理解的包括数值型(数字本身)、日期型,而文本型和逻辑型的数据则需要解释解释。
文本型的数据一般包括汉字、英文字母、拼音符号,还有一种就是上面提到的数字也可以作为文本型数据存在。例如100棵树里的100就会被默认为文本型数据。
至于逻辑型数据,则不在今天的讨论范围之内。
在Excel里,如何判断一个数字是数值型数据还是文本型数据呢?文本型数据与数值型数据最大的区别是,数值型数据可以进行运算(如加减乘除),而文本型数据不行。
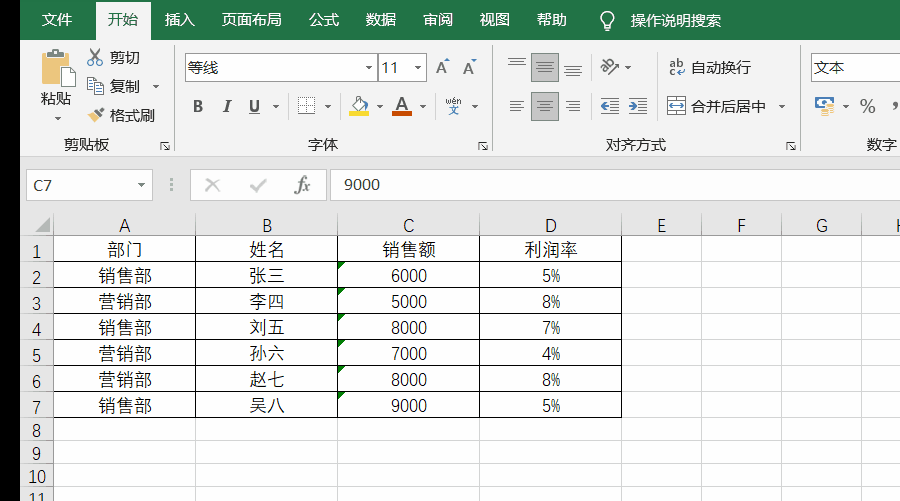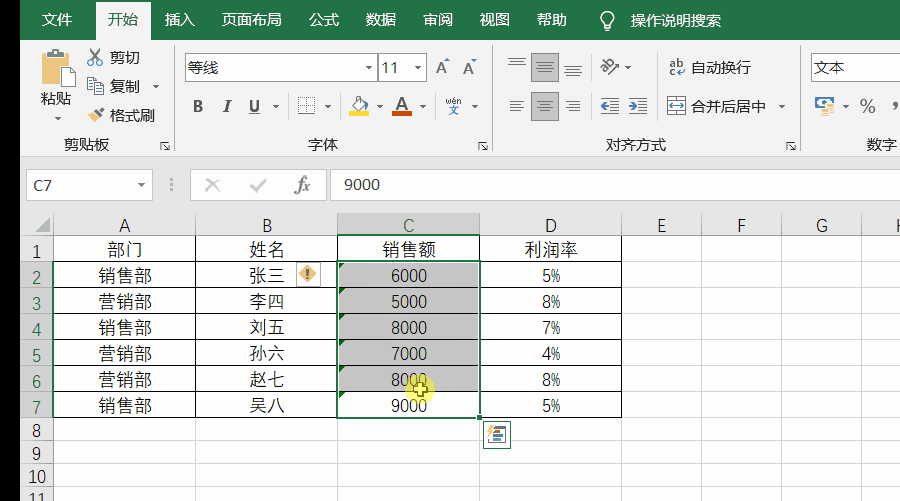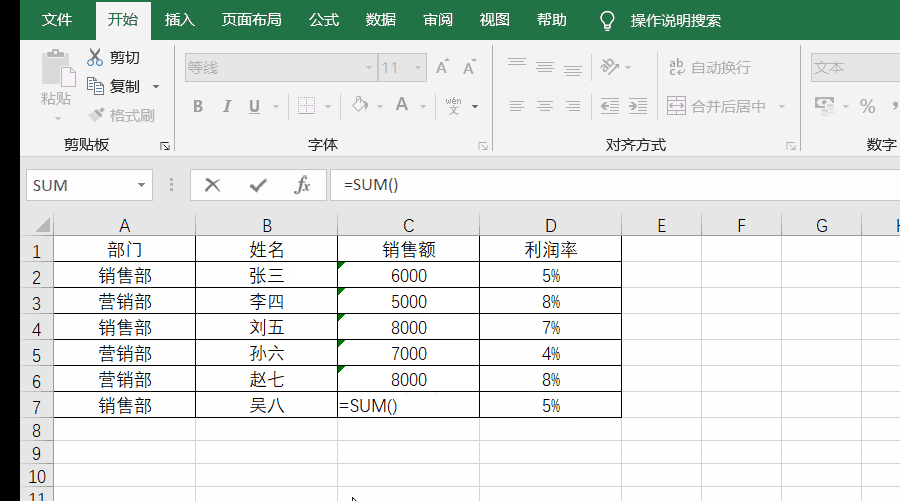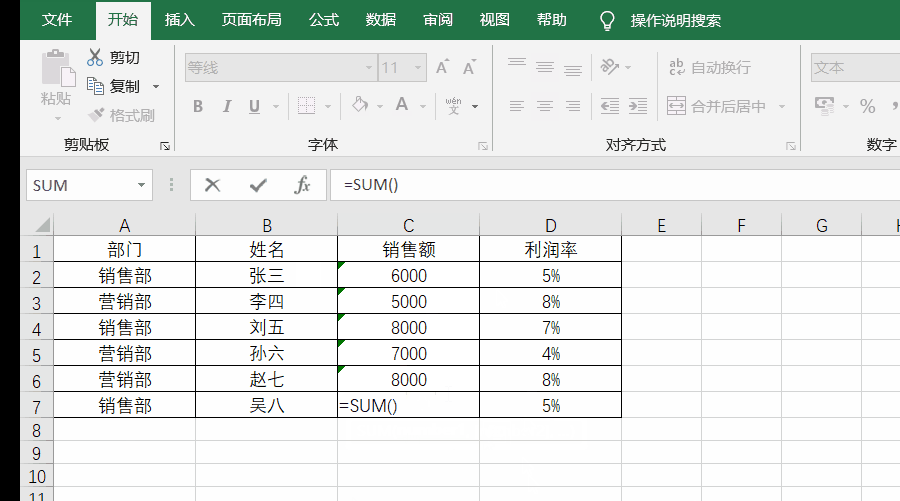
▲ Sum和函数无法计算文本数字
具体到一个表格上,文本类的数字左上角会出现绿色的三角符号。如下图所示。在数据量比较大的情况下,如果你无法确定有没有文本类的数字,可以对所有行/列进行总和运算,如果运算有错误,则表示存在文本型数字。

文本型数据处理
1.文本型数据的导入、整理
文本型数据导入的方法有两种。第一种是直接复制文本内容,粘贴到表格的第一列中;第二种则是先把内容在txt文档中进行整理,再从Excel进行导入。
要注意的是,使用这两种方法导入的前提,都需要把数据整理成整齐的格式,如下图所示。

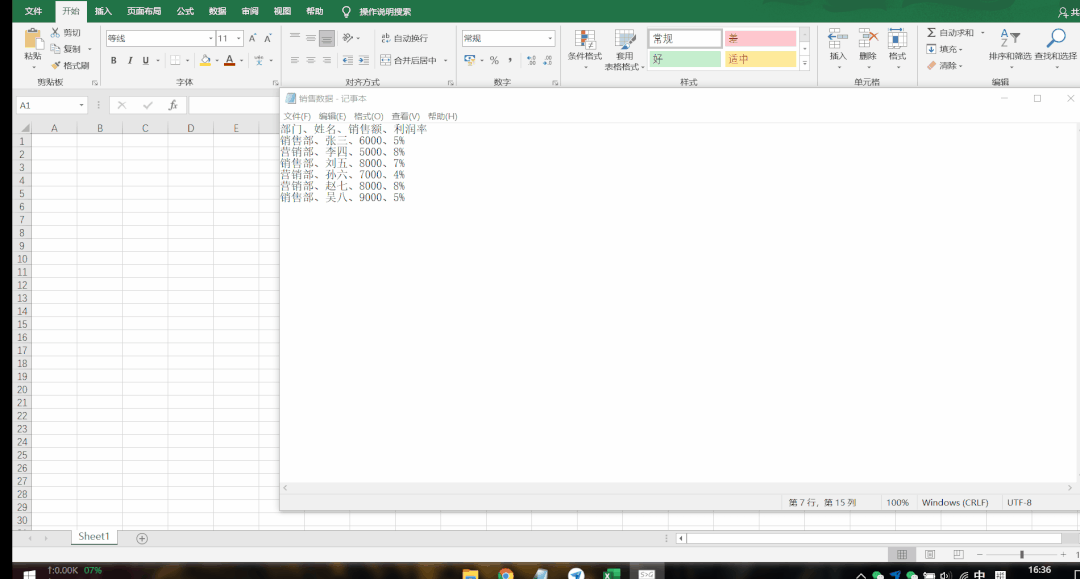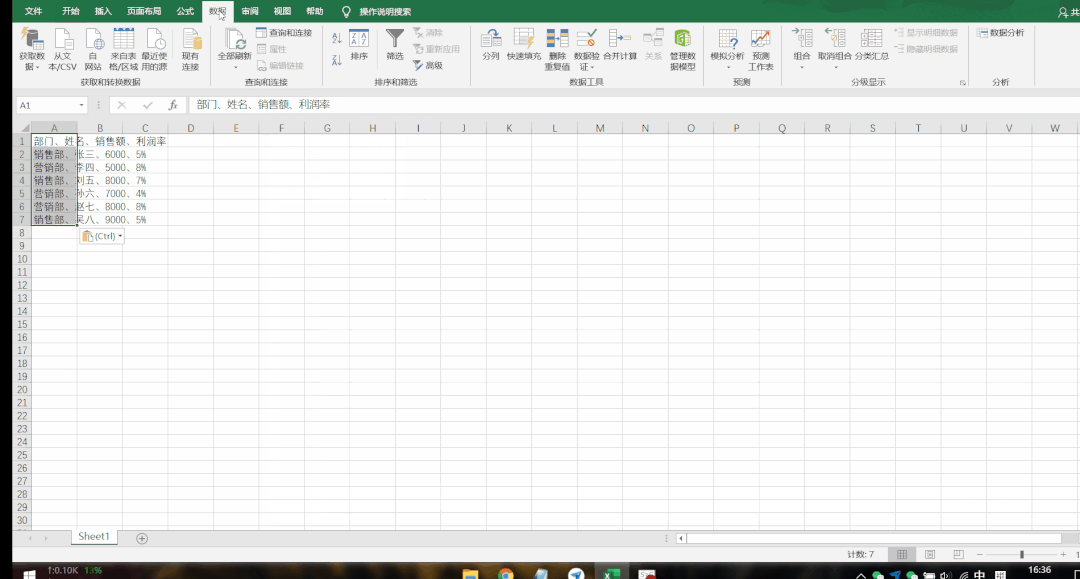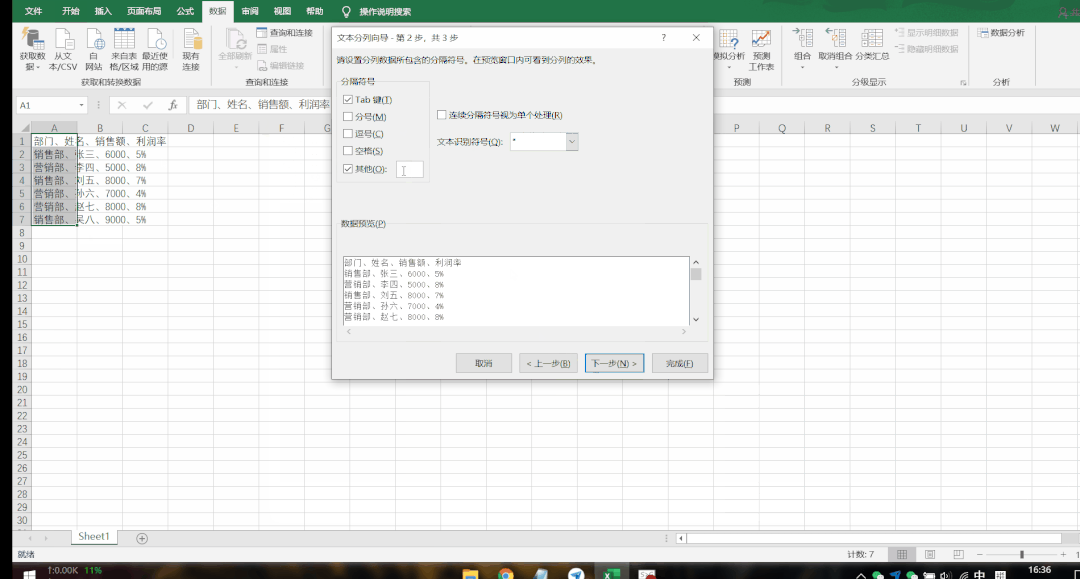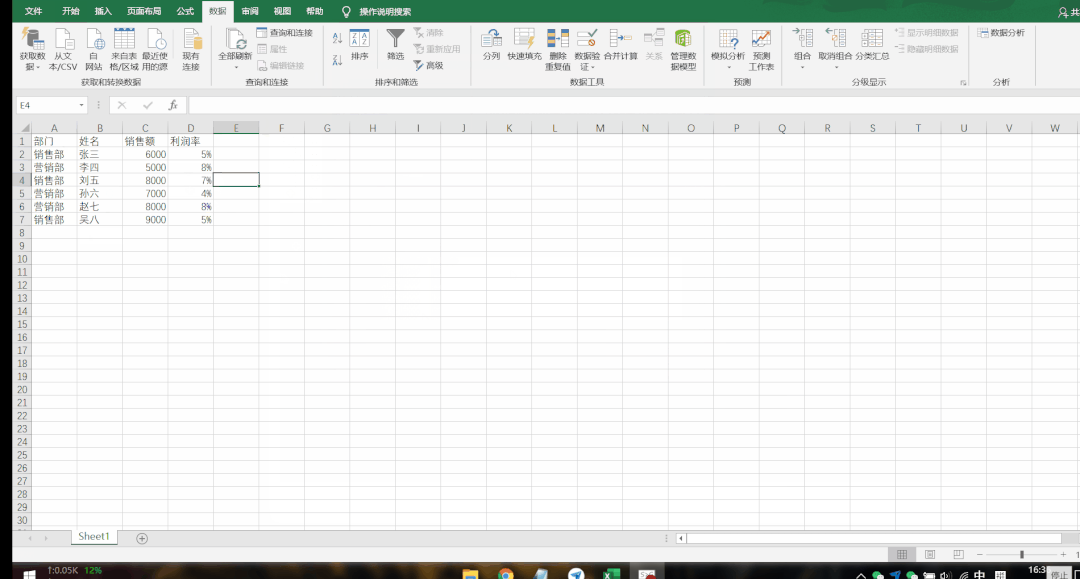
导入数据后,第一列的数据拥挤地堆叠在一起,下面要做的就是对其进行分列。在Excel上方工具栏“数据”下“数据工具”一栏中,找到“分列”按钮,点击后会出现这样的页面:

分隔符和固定宽度是两种不同的分列方式,在这个表格中,我们的分隔符就是“、”,而固定宽度的话,则是按照数据与数据之间的间隔进行分列。
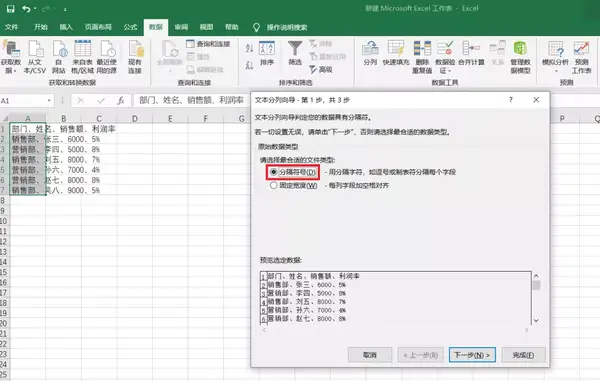
需要注意的是,在导入txt文档时如果出现文字乱码,要在导入选项的“文件原始格式”中选择“无”。

下面是两种方法的示范:
▲ 通过复制粘贴导入数据
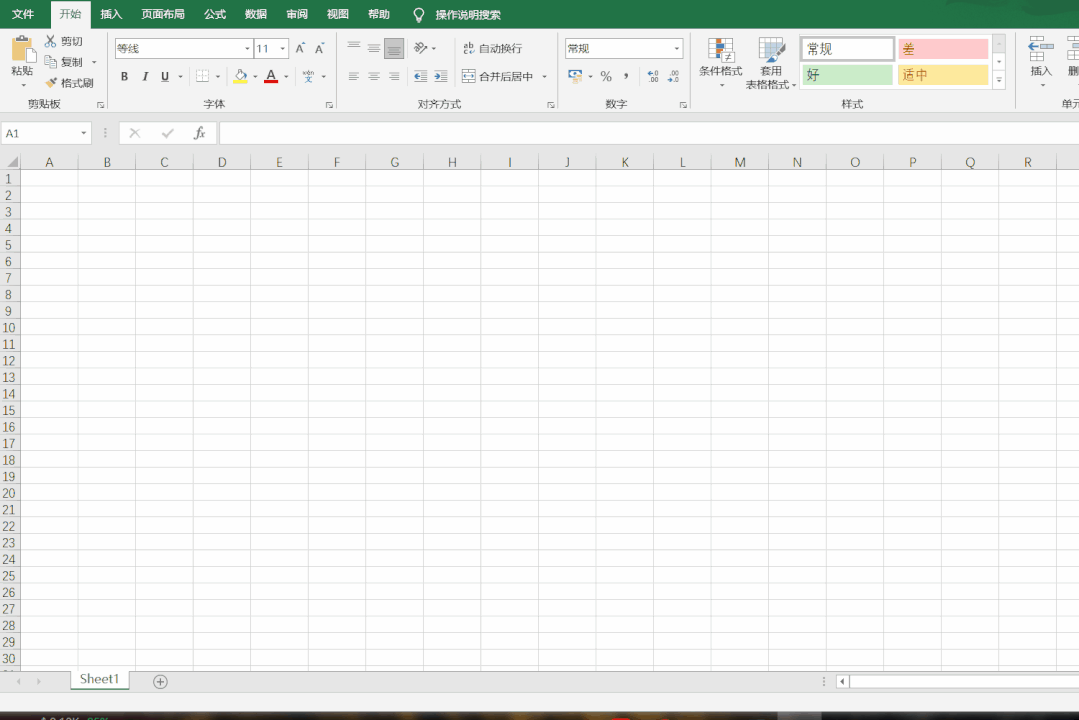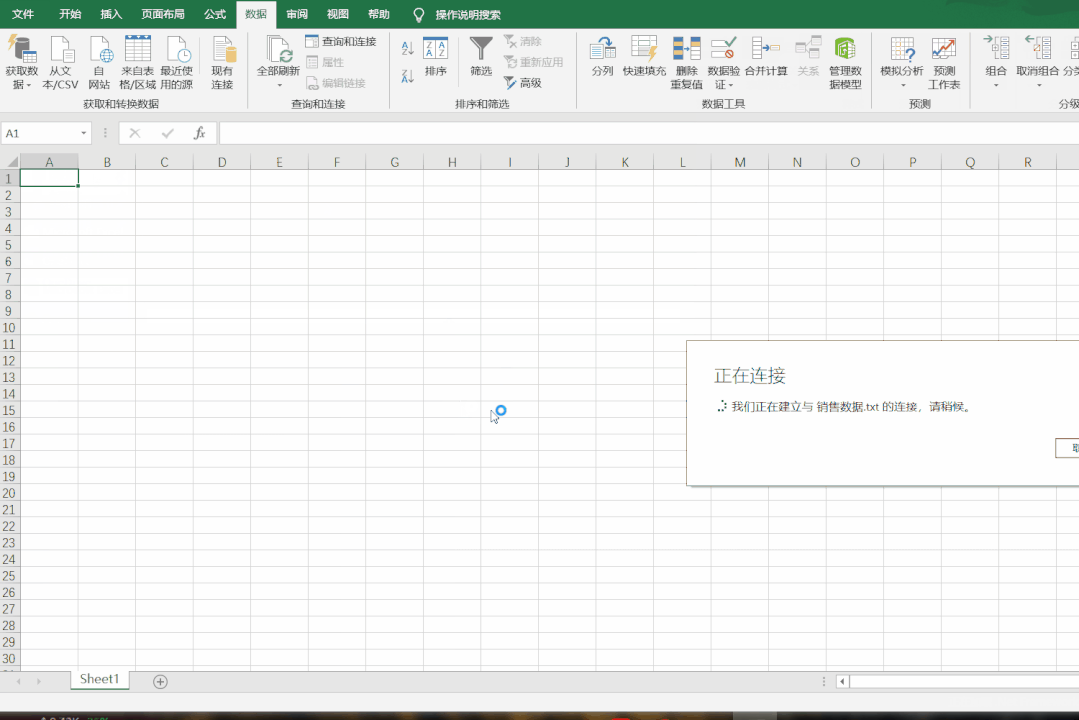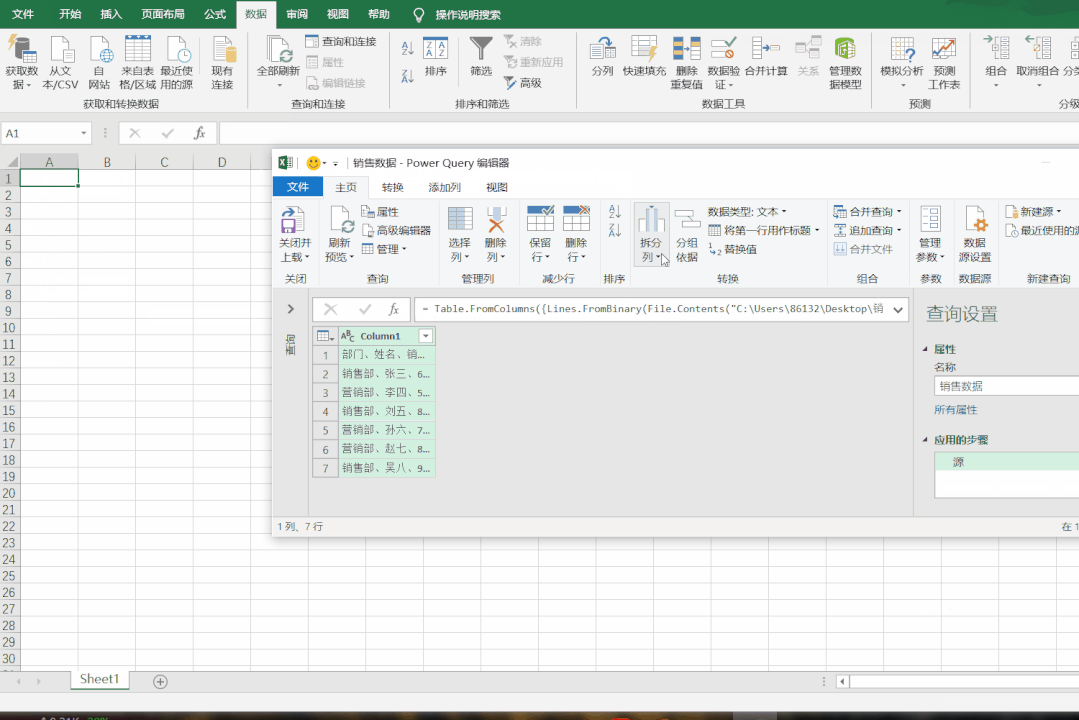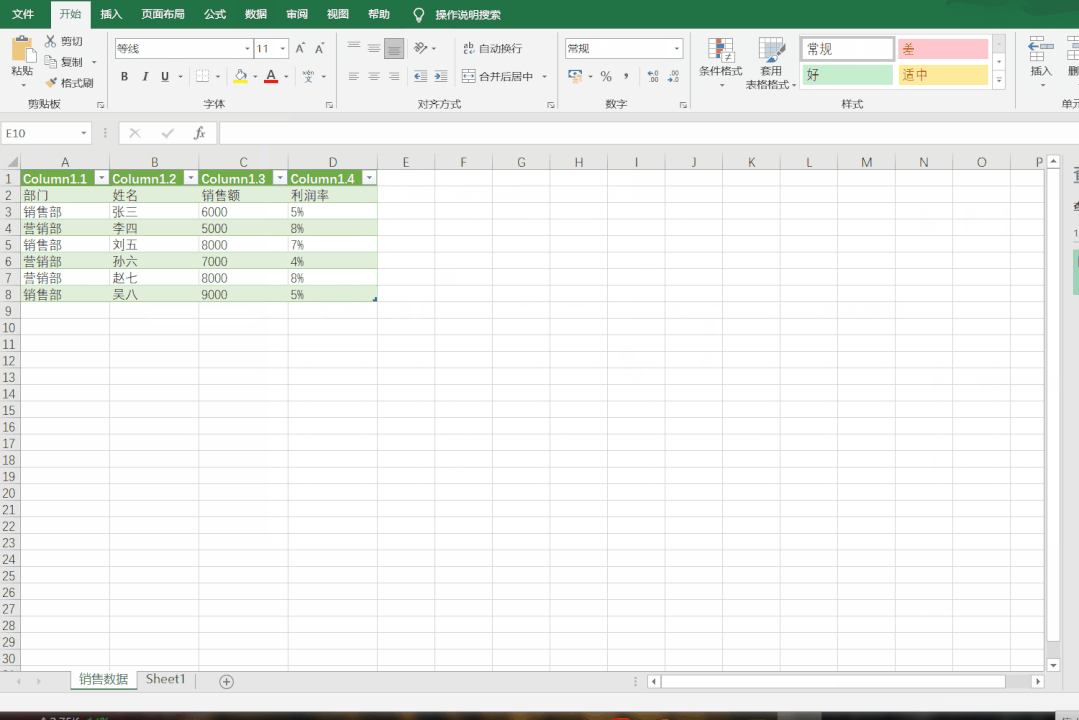
▲ 通过文本导入数据,由于限制减少了图片帧数
分隔后,我们有时候需要对其排序进行整理,我们可以使用Excel“排序和筛选”功能栏下的“多条件排序”,可以设置多个条件进行综合排序。
2.文本型数据的清洗
导入数据后,有时候我们会遇到某些数值型数字变成了文本或某些文本的数字变成了数值型。
这种情况下就需要对其进行清洗,就是要把这些数据的格式统一。我们既可以在导入数据的时候,选择“转换数据”,再对其数据类型进行调整,可以看到如下页面:

也可以在导入完成后,选中数据所在的选区,在“开始”的下方“数字”一栏中,选择数字的类型,如图。

而如果你是复制粘贴导入数据,则可以使用“选择性粘贴”,在对话框中选择“数值”或“文本”统一格式。
3.文本型数据处理方法
文本型数据比较常见的处理需求包括统计、查找和提取等。
- 统计:count函数
count函数的基本写法是count(value),其中value通常是指选区。count函数的作用是统计value选区中一共有多少个数据,并且只能是数值型数据(字)。
但有时候,我们的需求是对文本型数据进行统计,那么就需要用到counta函数,它的基本写法与count函数类似,为counta(value)。
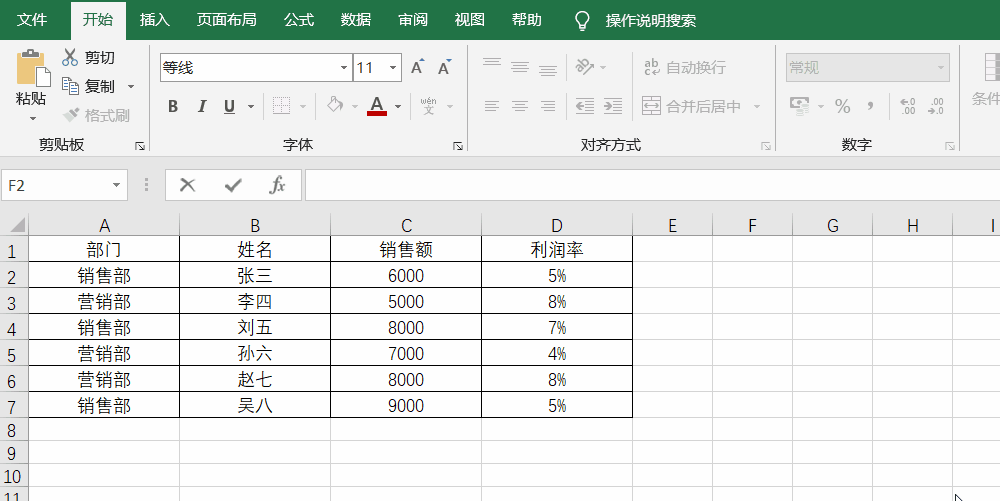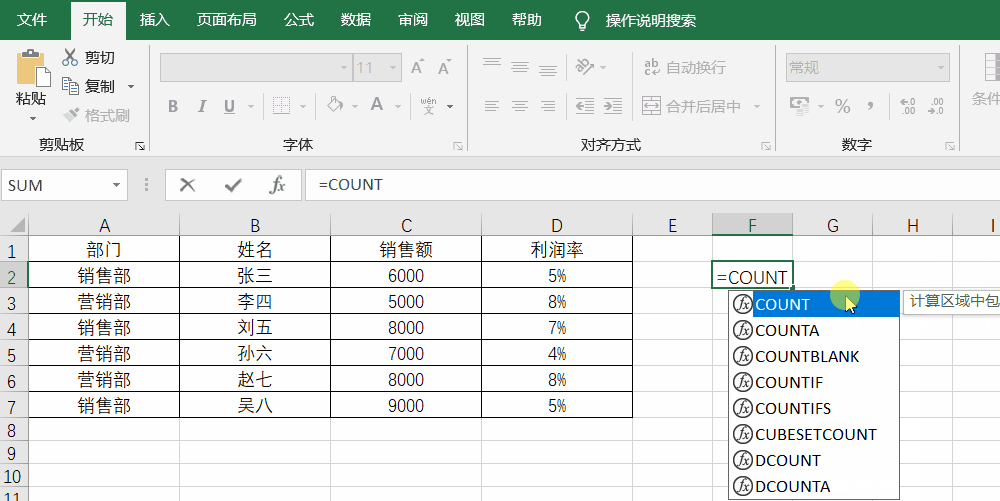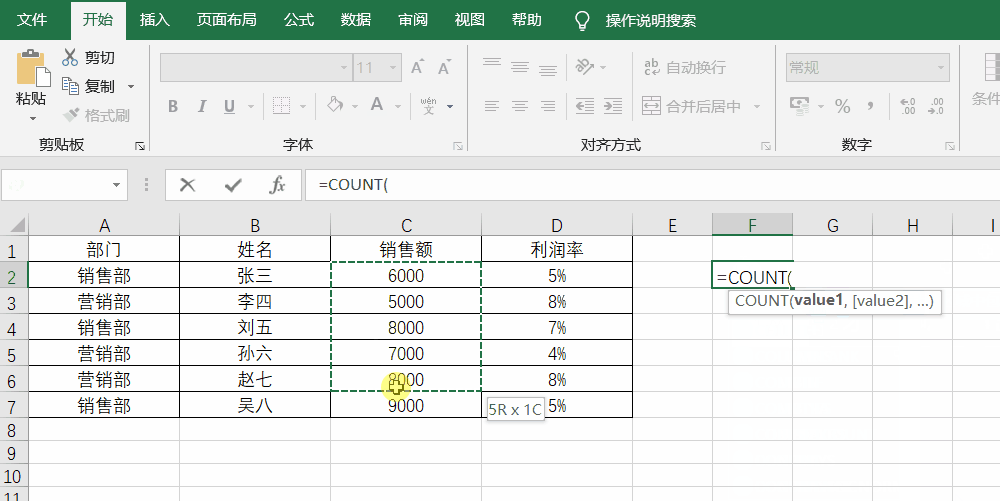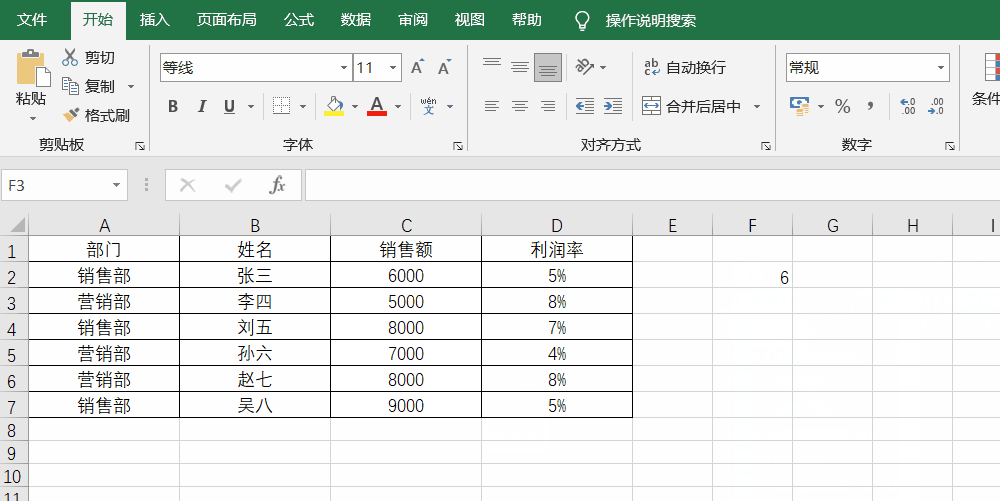
例如,要想统计一共有多少个人的销售额,就可以使用=count(C2:C7)
实操如下图所示:
当然,这还不行,因为我们统计数量总是有条件的,比如在上面的案例中,统计销售额大于7000的人数,就需要用到带条件的count函数,那就是countif函数,如果有多个条件,那么就是countifs函数。
countif函数的写法为countif(range,criteria)其中,range为选区,criteria为条件。销售额一列就是选区,销售额大于7000就是条件,也就是=Countif(C2:C7,">=7000")。实操如下图所示:
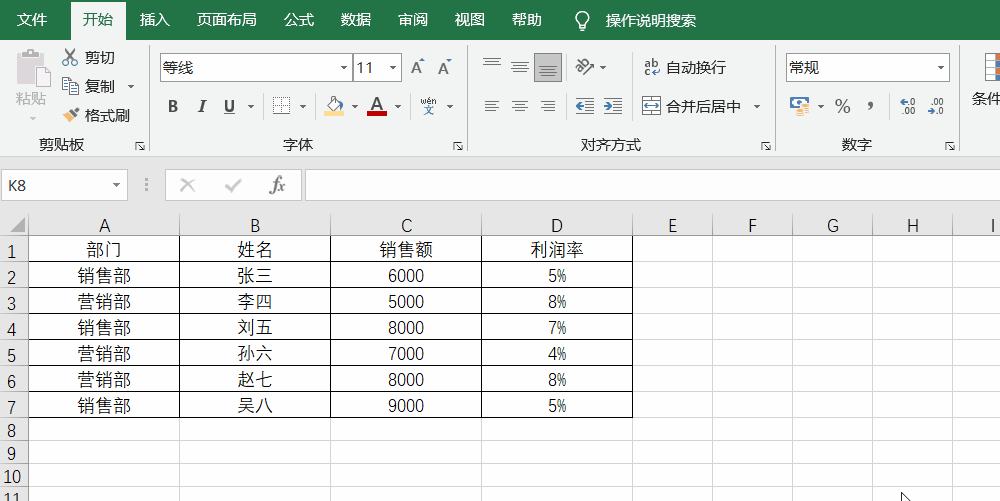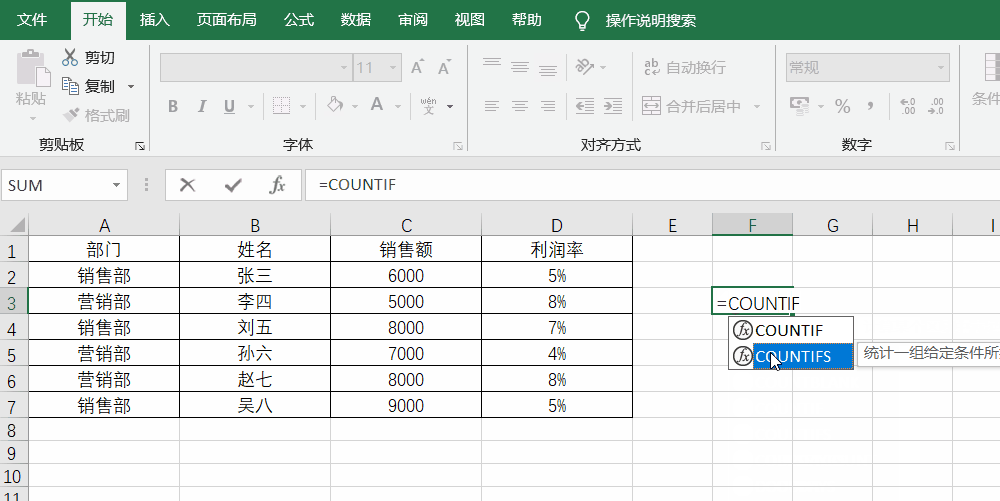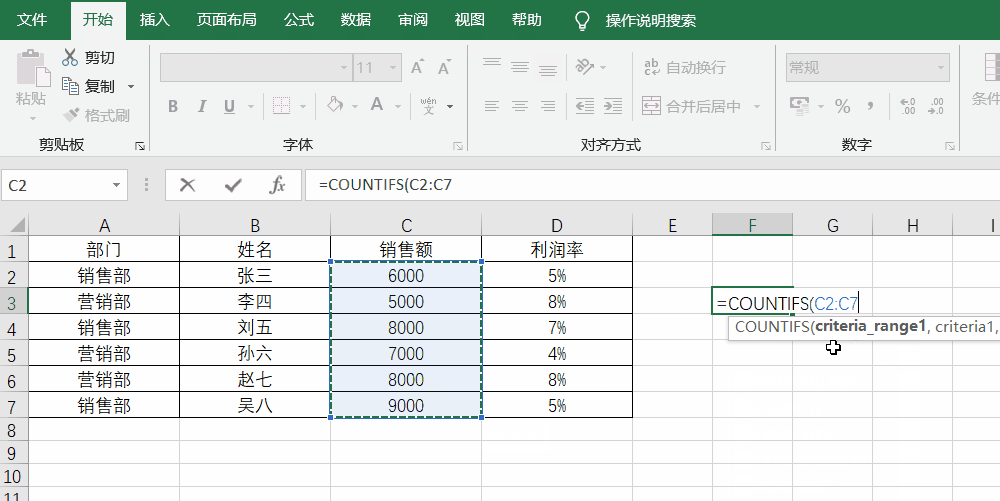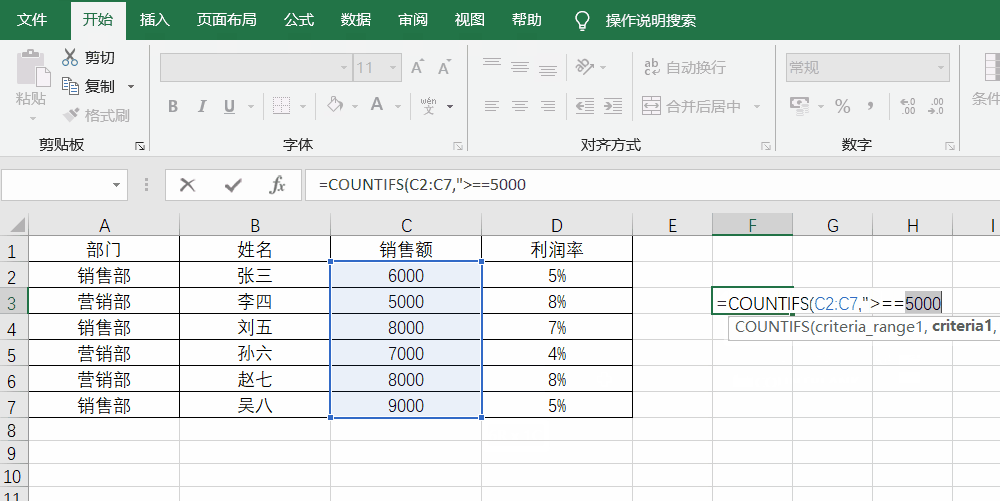
多重条件下的统计countifs函数的写法其实就是countif函数的组合,即countifs(range1,criteria1,range2,criteria2),如果想要统计销售额大于5000,且属于营销部的一共有多少人,就是=Countifs(C2:C7,">5000",A2:A7,"营销部")。
来看看实操:

- 查找:find/search函数
有时候,我们出于某种目的想要知道某个词/句子在某段话里的位置,我们虽然可以直接通过Ctrl F快捷键找到它,但是不知道它具体在第几个字的顺序。
这时候,就可以用到Find/search函数。find函数的写法是find(findtxt,withintxt,startnumber)。其中,findtxt就是要查找的那个词/句子,withintxt则是包含这个词/句子的文本,startnumbe是指从第几个字/数字开始查找,默认为1)
如果想要查询“的”在“中国的,也是世界的”这句话中的位置,就是=Find("的",A1,1)
下面是实操图:
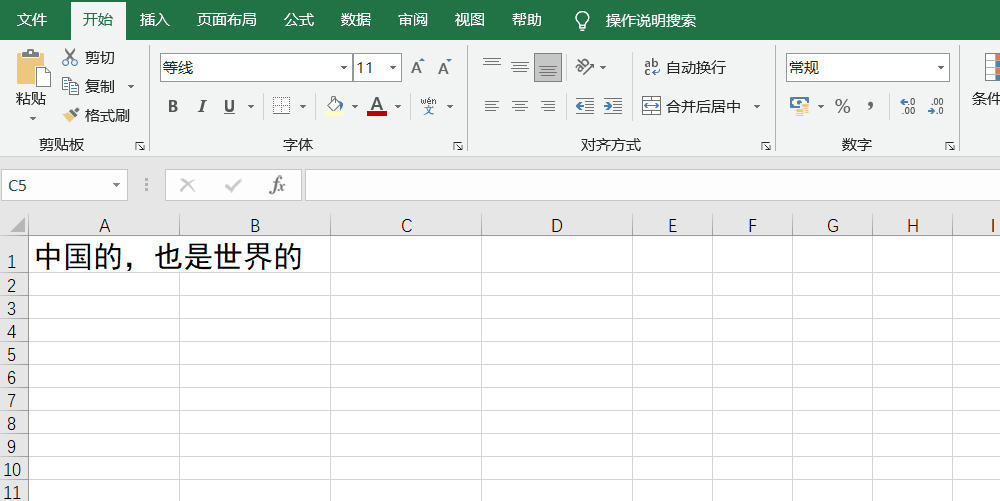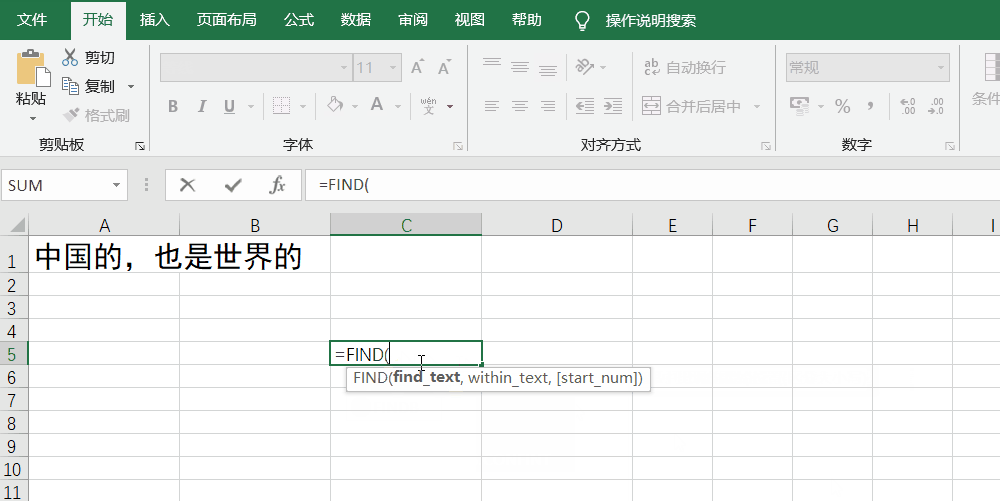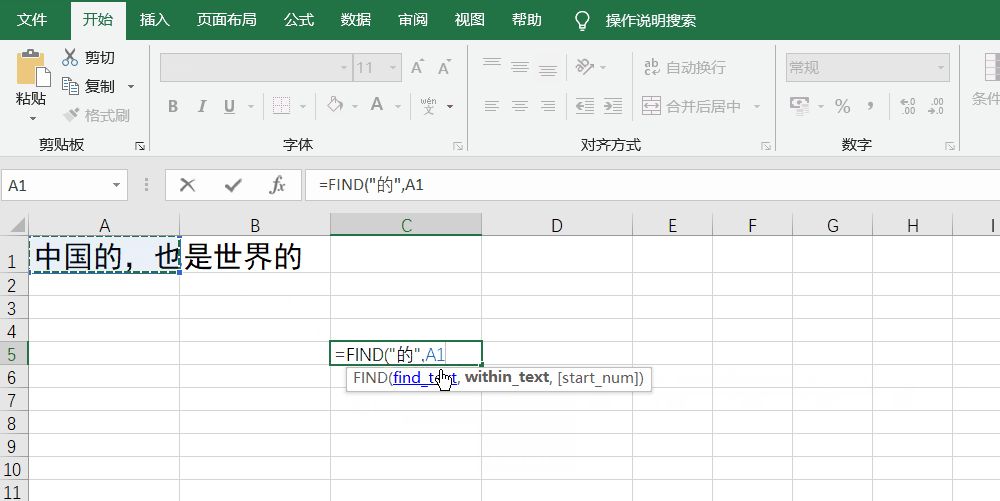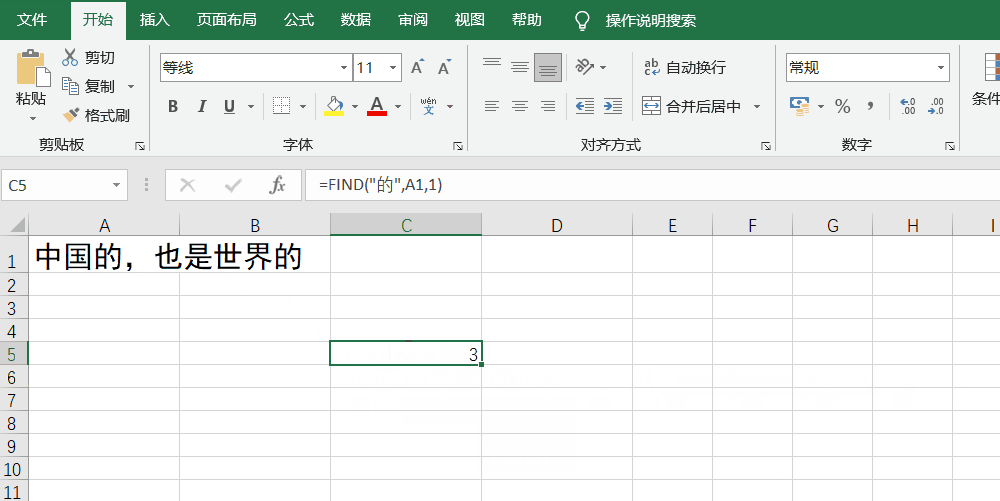
在这个基础上,search函数与find函数几乎没有什么区别,唯一的分别就是find函数严格区分大小写,而search函数则不分大小写。
- 提取:left/right/mid函数
说完了查找,下面就是提取。有时候我们需要提取某段文本某个顺序上的文字/数字,就可以用到提取函数。(不是中位数,中位数有专门的函数)
提取函数分为从左边/右边顺序,或某两段文本中间的文本,它们分别是left/right/mid函数。
left/right函数的写法是left/right(txt,number_chars),其中,txt就是源文本(即选区),number_chars是具体的顺序,如“数据分析是一门课”,要提取这句话从左往右的第3个字为止,就是=LEFT(A1,3)(A1是指Excel中A列1行里的文本),得出来的结果就会是“数据分”字。
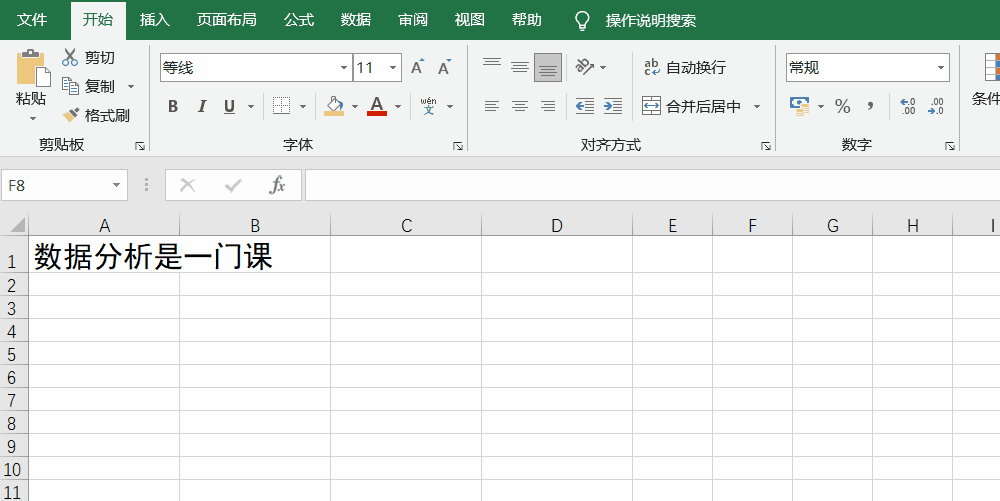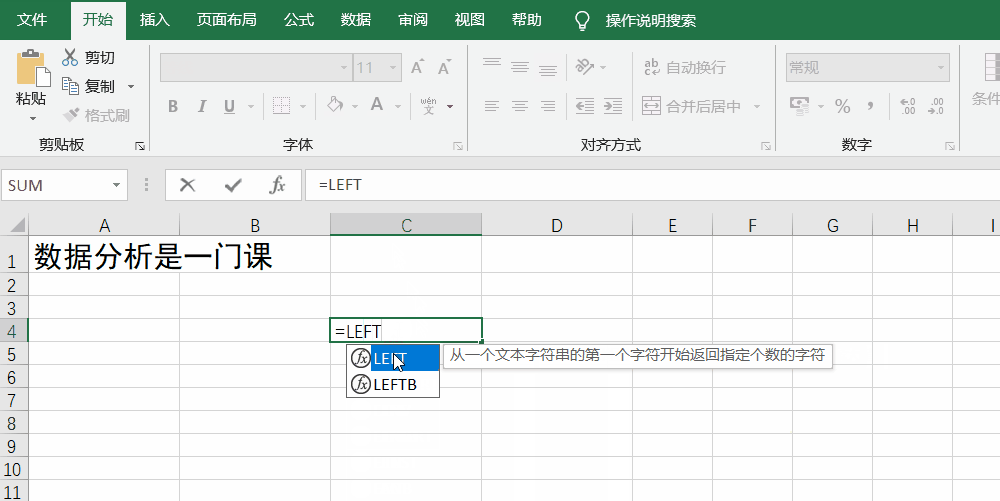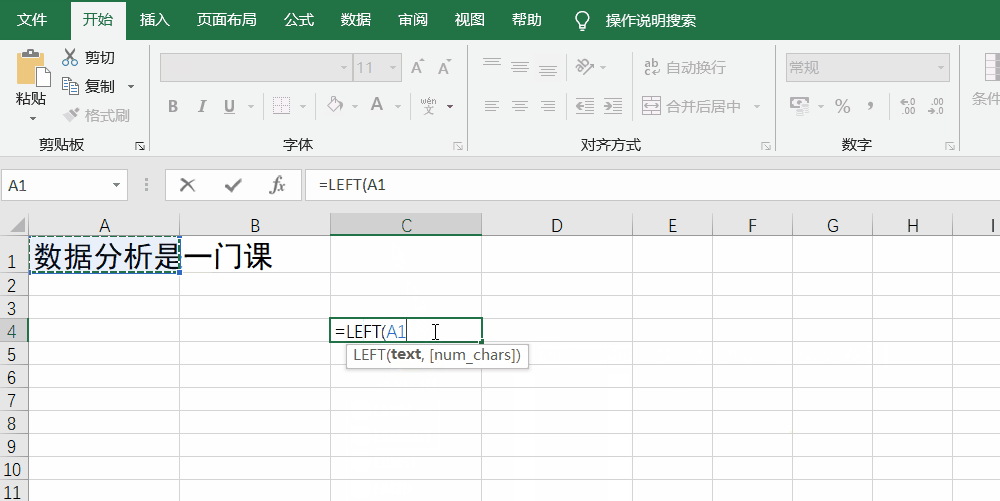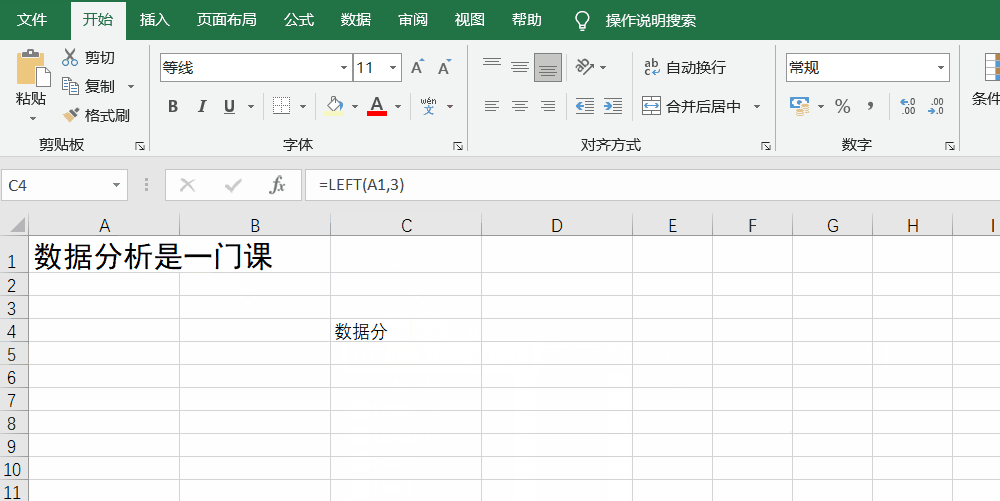
mid函数就有点复杂了,它的写法是mid(txt,start_num,num_chars),其中,txt是源文本,start_num是从第几个字/数据开始,num_chars则是提取的文本长度。例如想从第4个字开始提取2个字,则是=mid(A1,4,2),得到的结果就是“析是”。

如果有时候不知道具体的顺序是第几,还可以用Find函数先查找。
以上就是今天要分享的一些处理文本型数据的方法。
相关推荐
-
带公式的数据怎么复制?复制excel中设置了公式的单元格数据的方法
有时候复制一些单元格里的数据,可是复制过来的是一些公式,这是因为你复制的单元格里的数据是用公式得来的。今天我就分享在excel中设置了公式的单元格如何复制数据 1、打开要复制数据的表格。 2、可以看到 ...
-
Excel中比函数公式实现数据提取更好用的两种方法
本教程主要讲解了在Excel中比使用函数公式实现数据提取更好用的两种方法介绍,操作起来是很简单的,想要学习Excel的朋友们请跟着小编一起去看一看下文,希望能够帮助到大家. 例如下面的Excel数据源 ...
-

Excel如何快速核对两列数据是否一致(excel如何快速核对数据)
应用场景:核对两列数据的相同项和不同项,并用颜色标识出来.比如做库存盘点.数据核对等等.下面分享Excel秒速核对两列数据的7个方法,私信问了数据核对问题的小伙伴速来围观!方法1:选中需要核对的两列数 ...
-
excel中文本数字混合单元格里的数字怎么提取?
Excel是我们经常会使用的一款软件,我们常用它来计算各项明细支出.如果我们想要提取单元格里的数字要怎么办呢?单纯的提取数字很简单,我们这次来看一下文本和数字混合的情况下怎么提取单元格里的数字.方法如 ...
-
如何将excel表格中的公式数据设置为数值
我们Excel表格中带有公式的数据,想要设置为固定不变的数值,该怎么操作呢?今天就跟大家介绍一下如何将excel表格中的公式数据设置为数值的具体操作步骤.简单法1. 如图,打开Excel表格后,将第三 ...
-
excel表格中输入公式求和,但不显示数值怎么办
有时在excel表格中输入公式自动求和,但在求和的单元格中不显示数值?其实主要原因是需要求和的单元格的格式是文本而不是数值.下面小编分享一下自己的操作方法. 操作方法 01 打开需要自动求和的exce ...
-
Excel表格如何使用公式?
想要使用Excel表格中的公式的话,可以先在表格中输入一些数字,然后选中图示中的单元格,之后输入=B3+C3,按回车键即可,复杂点的公式运用的话,还是比较容易的,在图示单元格中输入=B3*C3+D3/ ...
-
怎么将Excel表格中的文本格式转化为数值格式
如果我们表格中的数据格式不统一,在排序时就会出现问题了,想要将文本格式转换成数值格式,该怎么操作呢?今天就跟大家介绍一下怎么将Excel表格中的文本格式转化为数值格式的具体操作步骤.1. 如图,在打开 ...
-
excel文本格式与数值格式的相互转换
在工作中我们经常需要将excel表中的文本格式转换为数值格式,或数值格式转换成文本格式.下面小编跟大家分享转换的全过程. 文本格式转换成数值格式 01 文本格式转换成数值格式是常有的事.所有文本格式的 ...
-
excel中数值格式怎样设置
因为电子表格应用程序是用来处理数值数据的,所以数值格式可能是工作表中最关键的部分,格式化数值数据的方式由用户决定,但在每个工作簿的工作表之间应使用一致的处理数字的方法. 操作方法 01 可以用来处理数 ...
