如何寻找合适的kol

webscraper简介
Web Scraper 是一款网页数据采集工具,只要是我们日常在网页上可以浏览到的内容,它都可以帮助我们爬取下来。
Web Scraper最大的特色是免费和免编程,不懂编程的人也很容易操作,尽管在爬取网页数据方面也有很多工具,但综合对比来看还是web scraper更加方便快捷一些。
Web Scraper主要有以下几个特点:
- 轻量级,只是浏览器插件,无需在电脑中安装
- 免费,并且没有按下载数据条数收费的要求
- 免编程,好上手,一天学会无压力
- 唯一缺点是免费版不能设置定时任务
webscraper下载
登录官方网站进行插件安装,插件有两种浏览器可供选择:火狐或者谷歌的Chrome。我选择的是火狐浏览器,如果选用Chrome浏览器,则需要科学上网。
(具体下载网址不方便粘贴,可以私信获取)
知乎关键字搜索信息爬取代码
{"_id":"zhihuchaxun","startUrl":["
https://www.zhihu.com/search?type=content&q=k30s至尊"],"selectors":[{"id":"question","type":"SelectorElementScroll","parentSelectors":["_root"],"selector":"div[] div.List-item","multiple":true,"delay":"3000"},{"id":"url","type":"SelectorLink","parentSelectors":["question"],"selector":"div [itemprop='zhihu:question'] a","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["url"],"selector":".QuestionHeader h1","multiple":false,"regex":"","delay":0},{"id":"view","type":"SelectorText","parentSelectors":["url"],"selector":"div.NumberBoard-item strong","multiple":false,"regex":"","delay":0},{"id":"follower","type":"SelectorText","parentSelectors":["url"],"selector":"button strong","multiple":false,"regex":"","delay":0},{"id":"answer","type":"SelectorText","parentSelectors":["url"],"selector":"div.Card:nth-of-type(1) a.QuestionMainAction","multiple":false,"regex":"","delay":0}]}
webscraper安装
下载好插件后,打开火狐浏览器,点击右上角的几个横杆按钮,然后点击附加组件
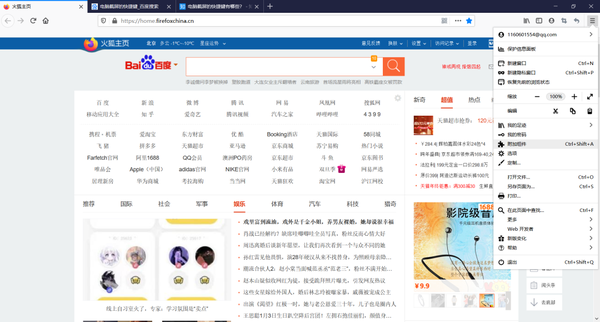
然后点击扩展
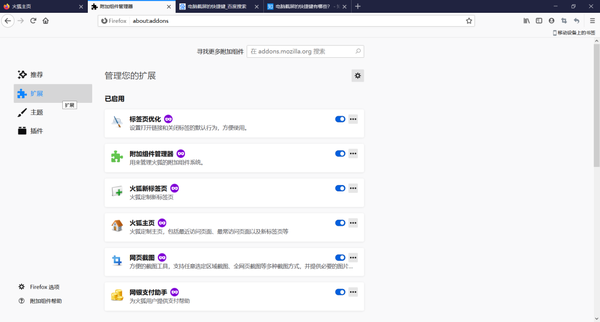
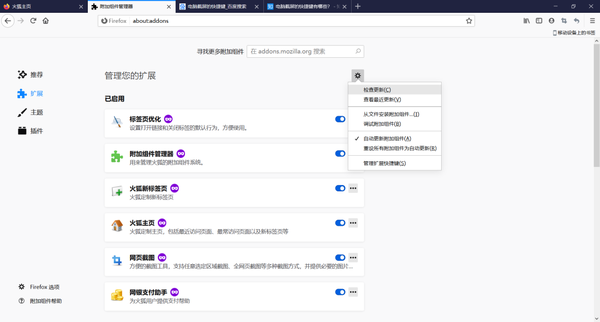
点击右边的齿轮,选择从文件安装附加组件
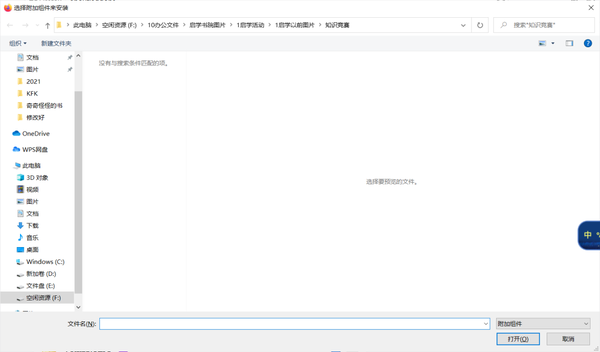
找到对应下载的插件位置,然后点击插件打开
插件显示安装完场,点击添加
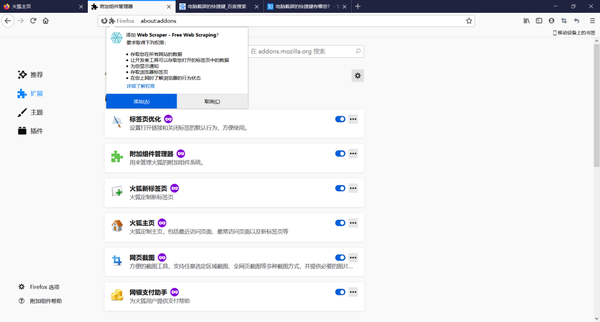
然后我们就可以看到浏览器的右上角有一个类似蜘蛛网的图标,说明webscraper已经安装完成。
webscraper使用
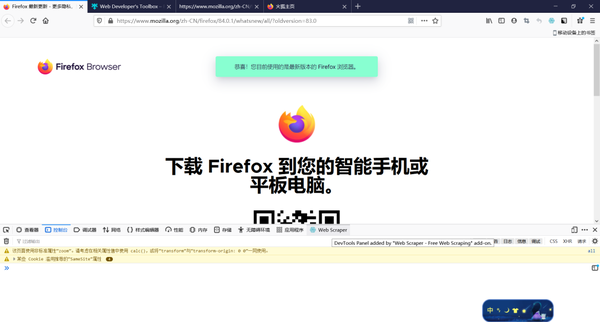
同样点击右上角的三个横杆,选择web开发者

然后点击第一个选项,切换工具箱
然后就可以看到浏览器下方出现了页面,点击最右边的图标就可以打开webscraper
然后点击import sitemap,导入搜索程序
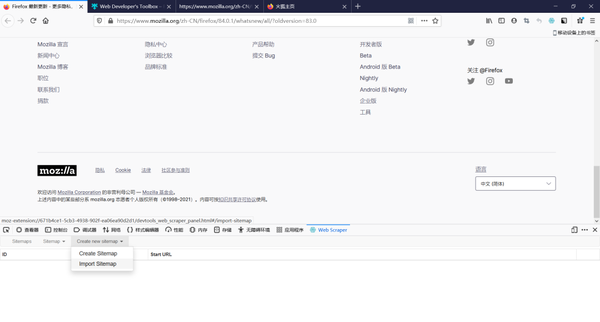
把知乎的爬取代码复制到上面的框里
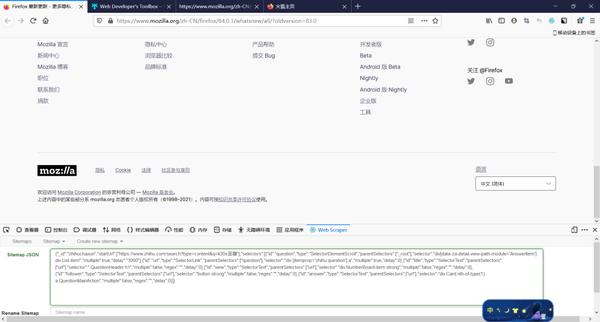
然后自己写个合适的名字(最好用英文,不支持中文),点击保存

然后就可以看到新建好的搜索程序了,直接点击搜索程序
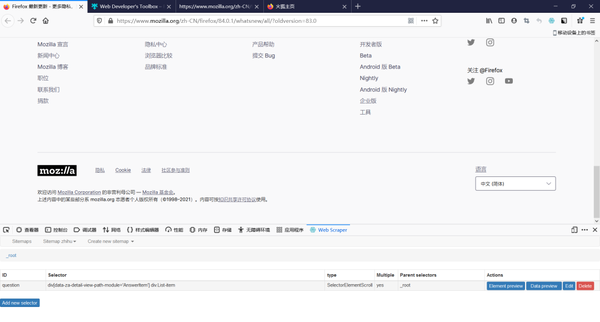
进去以后是这个界面
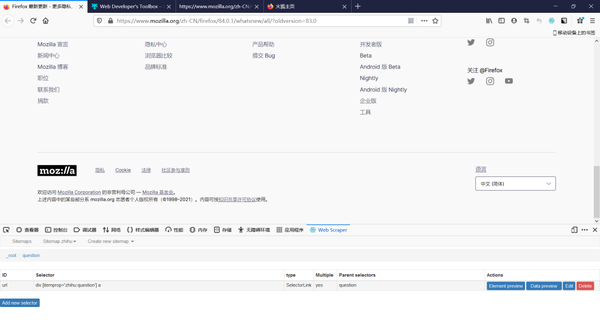
然后点击中间的选项,选择edit metadata修改搜索词

比如修改成搜索关键词“好物”然后保存
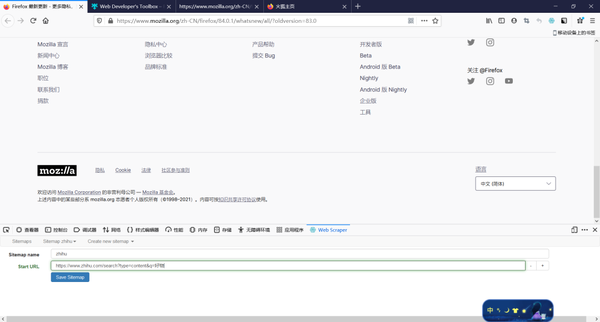
点击中间选择的scrape,开始搜索
按照默认设置,点击开始就可以了
接着我们会看到弹出一个新的页面框,并且页面框会自己动,不要关闭

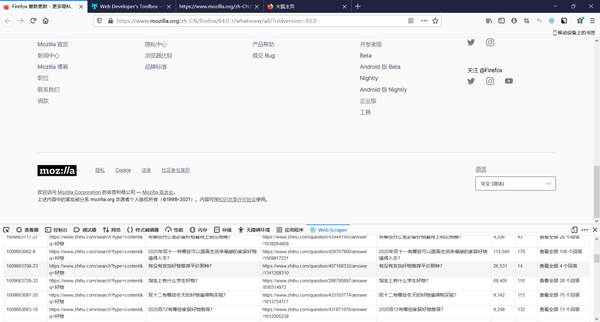
等什么时候页面框自己关闭,然后爬取信息就已经结束了,点击refersh可以查看爬取到多的信息

然后同样点击中间选项的最后一个选项,到出数据
然后点击download就可以下载到本地了。
然后打开表格就可以看到我们爬取到的数据了

通过对数据回答数和浏览数的筛选,我们就可以选出,回答数较少,浏览数较多的问答进行回答了。

相关推荐
-
DOTA2新手必看 寻找合适定位发挥超神攻略
DOTA2新手必看 寻找合适定位发挥超神潜力 操作方法 01 玩过DotA和类DotA对战游戏的玩家应该都知道游戏里大多数时候是分工明确的,下面将给刚接触<DOTA2>的新手玩家介绍游戏里 ...
-
我的世界有哪些燃料?怎样寻找合适的燃料?
在我的世界游戏中,烧制矿石.食物或是其他东西也是很有意思的游戏环节之一,不过要烧制物品的话,就要先找到燃料,那么接下来就为大家介绍一下我的世界里有哪些可以使用的燃料,再说一说该怎么样去寻找到合适的燃料 ...
-

小红书的规则和推荐机制玩法(小红书怎么收录关键词)
很多品牌方对小红书平台营销的印象就是-种草.如果品牌想做种草,首选的肯定是小红书平台.其实小红书平台营销还有很多玩法,媒介匣就整理了小红书平台的广告推广模式,让你更加深入的了解小红书.品牌要想玩转小红 ...
-
用OpenSolaris和ZFS搭建家用NAS的方法(图文教程)
OpenSolaris(点击下载) 和 ZFS 为我们提供了一个机会用通用计算机硬件和开源软件搭建针对个人和家庭的小型NASBox,我这个DIY迷当然不会放过这个机会啦。此次 DIY我制定的基本目标是 ...
-
美图秀秀虚拟化妆新体验 精致美瞳打造深邃眼眸
彩妆的重点是眼部,但要妆容升级,还需美瞳来配。只有眼妆细致到搭配瞳孔的颜色,或许你已晋升为升级版的彩妆达人。而美图秀秀是目前比较热门的图片处理软件,很多MM都通过美图秀秀找到了自信。今天就与大家一起来 ...
-
360误删文件恢复 360误删的文件怎么恢复
简介 有很多网友在使用360安全卫士的时候,经常会误删掉很多文件,为此我把自己一些常见的知识奉献给大家吧。 工具/原料 360系统急救箱 一键还原工具 数据恢复软件 方法/步骤 一、记忆法 把自己误删 ...
-
如何使用360安全卫士恢复误删文件
清理电脑垃圾不小心误删了文件,怎样快速找回呢?我们可以借助360安全卫士来实现恢复误删文件,请看下面的方法教程。 360安全卫士恢复误删文件教程 一、工具法 利用360安全卫士中的360系统急救箱进行 ...
-
金山WPS文字排版通用必备技巧指南分享
借助软件“生产”出啧啧称赞的页面才是最终归宿。请跟我一起来用各路招数编排一页文稿。要知道,只有精美的页面呈现在您的面前,那才是响当当的硬道理。我们边说边用,您来仔细体验WPS2012文字给我们带来的方 ...
-
捷速ocr文字识别软件怎么使用 捷速ocr文字识别软件使用图文教程
小琪每天做的最多的事情就是自拍,端着手机寻找合适的角度玩自拍已经成为她生活中不可或缺的一部分。甚至影响到了工作,通常人们都会选择扫描的方式处理一些文件,但是小琪使用的是手机拍照的方式进行处理。这些图片 ...
-
2015春运抢票软件哪家强?百度抢票软件对比360浏览器抢票专版
近年来随着春运压力越来越大,124306远远不能满足人们的需求了。市场上的抢票软件也层出不穷,百度、360、猎豹、UC等都是各显神通。2015年随着12306宣布提前60天抢票,目前值得关注的两款抢票 ...
